
本文针对数据中心的能源消耗问题,根据数据集大小使用部分磁盘建立 RAID 以节省能源
ThinRAID: Thinning Down RAID Array for Energy Conservation
DOI: 10.1109/tpds.2014.2360696
TPDS' 2014
简介
一句话总结
本文针对数据中心的能源消耗问题,根据数据集大小,使用部分磁盘建立小型 RAID。其他非必需磁盘被停转以节省能源;当建立的预测模型预测工作负载变高时,通过新提出的 ES 数据迁移算法,将常用数据将迁移到待启动磁盘上以减少数据迁移量,同时平衡活动磁盘的工作负载。
先前的工作
作者提到先前的节能工作包括:关闭 RAID 部分磁盘实现节能、采用多速磁盘进行磁盘减速、优化数据布局以及数据缓存等方案。关闭 RAID 部分磁盘可以实现节能,但关闭多个磁盘会降低 RAID 的磁盘并行性,还会产生新的问题如:不能直接访问条带的部分块,或同一条带的多个块存储在同一磁盘上,从而影响空间局部性,文章称其为:条带退化;还有的方案通过使用 Multi-speed 磁盘节能,因为磁盘在不同旋转速度下功耗不同,但因为会较大改变现有磁盘的磁头结构,在制造上存在困难,没有被广泛部署;EERAID 通过使其中一个磁盘关闭来节省能量,通过对活动磁盘中的块进行 XOR 来处理在休眠磁盘上的请求,当活动磁盘在低功耗模式下发生故障,数据就会不可用,因此 EERAID 会存在大额外开销以及低可靠性的问题;PARAID 可以归为上周讲的 Geared RAIDs 中,关闭一个磁盘就是换一档,通过改变活动磁盘的数量来节能,问题在于会破坏空间局部性(空间局部性 Spatial Locality:在最近的将来将用到的信息很可能与正在使用的信息在空间地址上是临近的;同一个条带的块在同一个磁盘上,访问这两个块将显著增加磁头移动的距离,从而导致条带退化。)以及导致额外的开销(大量数据迁移以及更新奇偶校验)。
创新点
而本文的 ThinRAID 的创新点在于,根据数据集的大小,用 RAID 的部分磁盘建立小型的 RAID,建立了预测模型,预测下一个阶段的工作负载以确定待启动的磁盘数量;然后新提出了一个数据重组算法,优先迁移具有更高热度的数据到待启动磁盘上,以最小化数据迁移的开销。
贡献
文章的贡献包括:
一种新的节能策略,即所有数据都将集中在磁盘的一部分,而其他磁盘则关闭电源以节省能源;高工作负载时,休眠磁盘将启动以服务高负载
固定条带宽度的 RAID 扩展方案,可以减少数据迁移和奇偶校验更新的次数。扩展后,原条带的宽度不变,迁移数据留下的空间用于构建新的条带
(条带宽度就是磁盘的个数,横着的一行为一个条带)一种功率控制策略,它确定了待启动磁盘的最佳数量,以在最低能耗的情况下保持峰值性能;一种高效的小型数据迁移算法(ES 数据迁移),最大限度地减少数据迁移,并确保所有活动磁盘之间的工作负载平衡
在 Linux 内核中实现,实验结果表明,与传统 RAID 相比,ThinRAID 可以节省 15-27% 的能耗;与 PARAID 相比,可以获得 62% 的性能改进
背景
文章的背景是一些对 PARAID 的分析和观察结果,以引出本文的 ThinRAID 的设计思路和目标。
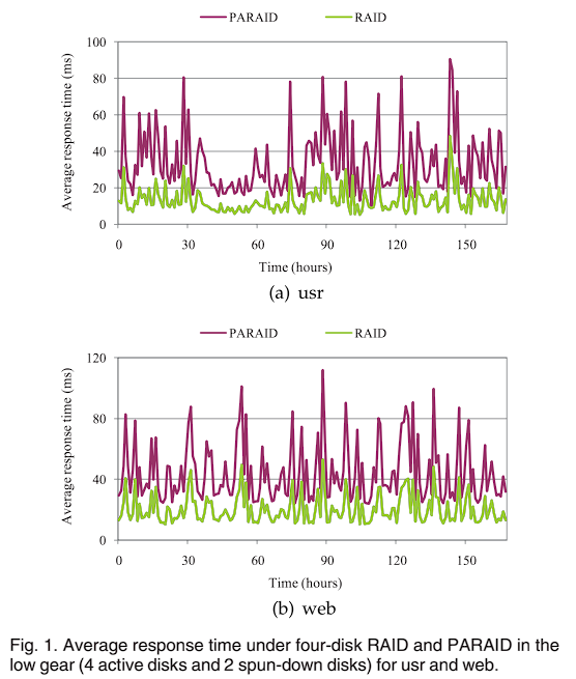
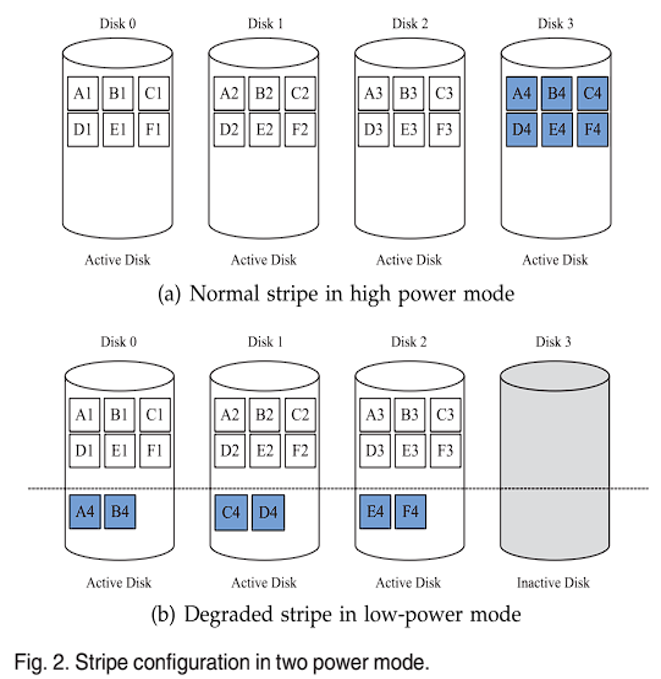
PARAID 的主要思想是针对不同的工作负载级别,使用 RAID 中不同数量的磁盘,组织成不同的档位,以在不同的功率模式下运行,从而满足不同负载水平的需求。此外,活动磁盘上的可用空间用于存储待休眠磁盘的数据副本,从而能够关闭待休眠磁盘以节省能源。作者的观察结果表明,PARAID 性能下降的主要因素不是磁盘并行性降低,而是 RAID 条带退化。图 1 比较了传统架构的 4 磁盘 RAID-5 和 PARAID 在低速档(4 个活动磁盘和 2 个休眠磁盘)下的性能,控制两个 RAID 的磁盘并行性相同,对于两种工作负载,PARAID 的平均响应时间分别比 RAID-5 大 152% 和 120%,因此磁盘并行性不是性能下降因素;图 2 是条带退化影响 PARAID 性能的图示:由于其中一个磁盘将要休眠,因此该休眠磁盘上的数据将迁移到其他活动磁盘的空闲空间中,导致同一条带的数据块存储在了同一个磁盘上,从而产生了条带退化。例如:将 A4 副本迁移到 Disk0 后,同一条带的 A1 和 A4 存储在同一磁盘的不同分区上,因此,访问这两个块将显著增加磁头移动的距离,影响了空间局部性(空间局部性 Spatial Locality:在最近的将来将用到的信息很可能与正在使用的信息在空间地址上是临近的),从而导致条带退化。而 ThinRAID 则从具有固定条带分区的一小部分磁盘开始,当工作负载变大时,将高热度数据(常用数据)迁移到待启动磁盘上,无论在低功耗还是高功耗下,条带的宽度都不会大于活动磁盘个数,因此同一条带的块不会存储在同一块磁盘上,也就是 ThinRAID 通过构建更小的条带来避免条带退化。
于是作者对 ThinRAID 的设计目标包括:在性能方面,避免条带退化,保持峰值性能;在能源效率方面,使多个磁盘休眠,节省能源,同时仍能够满足性能要求;在可靠性方面,能够保留标准 RAID 的可靠性,构建一个随着系统利用率增长而线性扩展的 RAID 架构。
ThinRAID 设计
ThinRAID 可以用于不同的 RAID 编码方案(RAID0、1、10、5、6),本文主要讨论的是 RAID-5。
Capacity-Adaptive ThinRAID
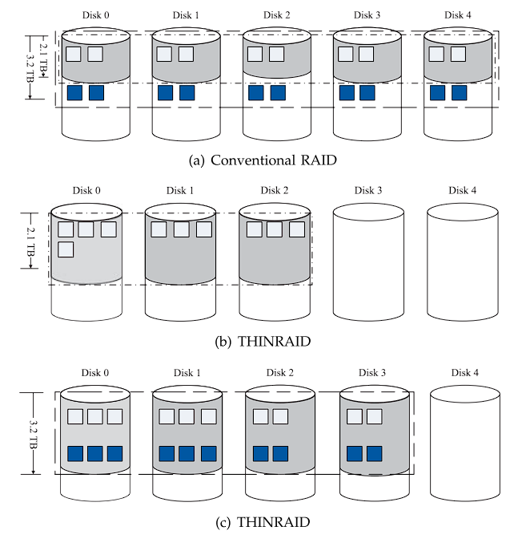
ThinRAID 能耗与活动磁盘数量有关,活动磁盘数量基于数据集的大小。每个磁盘容量为 1TB,初始数据集总量为 2.1TB,包括数据块和校验块。传统 RAID 会将所有数据分布到 RAID 每个磁盘中(如图 3a 所示),可能会导致磁盘容量和性能的低效使用。而 ThinRAID 不会过度分配存储资源,而是将所有数据集中在活动磁盘集合上,当负载较低时,其余磁盘可以关闭,从而节省整个存储系统的功耗。图 3b 显示了 ThinRAID 示例,使用三个磁盘构建 RAID。当需要扩展 RAID 架构时(比如添加新磁盘),ThinRAID 将使用下一页将会说明的固定条带宽度扩展方案来扩展磁盘以允许更多的空闲存储空间。如图 3a 所示,当数据集扩展到 3.2TB 时,传统 RAID 仍然将所有数据分布到所有 5 个磁盘上。ThinRAID 将使用 4 个磁盘,如图 3c 所示。扩容后,新旧块均匀分布到所有活动磁盘。
Preserving Peak Performance
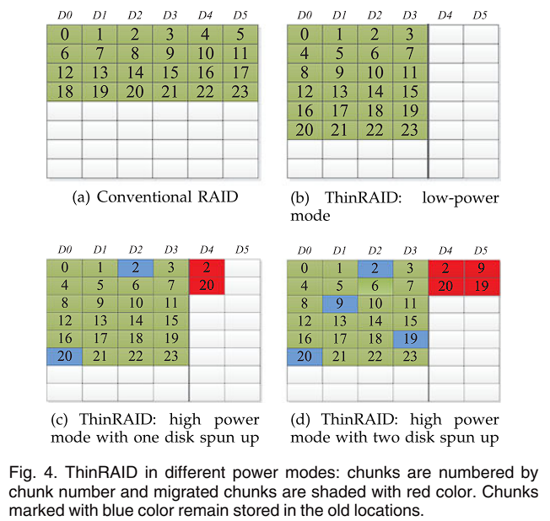
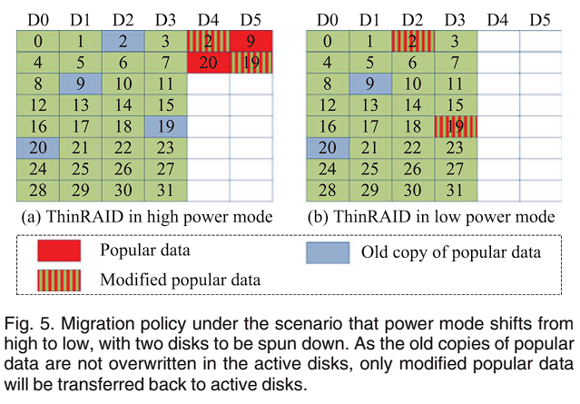
图 4 展示了分别具有 6 个磁盘的传统 RAID 和 ThinRAID 的示例。图 4a 中,对于传统 RAID,条带宽度为 6,所有磁盘都处于活动状态。图 4b 中,ThinRAID 将所有数据集中在 4 个磁盘上,并且工作负载也集中在这 4 个磁盘上,条带宽度为 4,关闭其他两个磁盘以节省能源。工作负载变高时,休眠磁盘启动,如图 4c 和 4d,少量高热度数据通过数据迁移算法被迁移到新启动的磁盘上,并平衡工作负载以保证性能,但这些高热度数据仍然在原活动磁盘上留有副本,没有被覆盖(迁移后,块 20 的副本仍然存储在磁盘 D0 上);工作负载变低时,多个磁盘准备休眠,待休眠磁盘中的高热度数据回传至活动磁盘。因为原活动磁盘中高热度数据的副本没有被覆盖,所以只有修改过的高热度数据才需要重新写回原活动磁盘,这样可以减少数据迁移量。如图 5 所示,块 9 和块 20 没有被修改过,因此不需要将它们重新写回原活动磁盘 D0 和 D1。
Fixed Stripe Width Scaling
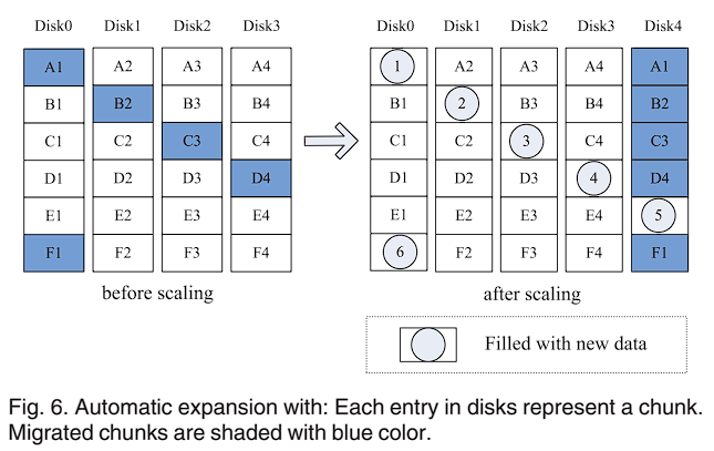
用于向 RAID 阵列中添加新磁盘。考虑添加 N 个磁盘到 M 个磁盘的 RAID:RAID 传统扩展方法是在添加磁盘后基于 Round-Robin 来分配数据。但通过这种方式,条带宽度将扩展到 M + N,同时几乎所有的数据块都会被迁移,奇偶校验需要更新,导致开销很大;ThinRAID 的方案则是保持迁移后条带宽度不变,旧数据块留下的空间用于构建新的条带,因此,RAID 扩展后仍然具有M的条带宽度,且不需要更新旧奇偶校验。每个条带的迁移块的数量是有限的,不能超过新添加的磁盘数量。数据只从旧磁盘迁移到新添加磁盘,不可在旧磁盘之间进行数据迁移。图 6 显示了 ThinRAID 中从 4 个扩展到 5 个磁盘的示例。第 1 个条带,块 A1 迁移到新添加磁盘 Disk4;在迁移之后,包括块 A1、A2、A3 和 A4 的旧条带没有奇偶校验更新且仍然具有条带宽度 4,其他的条带也是如此。这些块留下的空间则用来构建新的条带。这个方案可以大幅减少数据迁移的开销,同时,由于迁移是基于特定规则的,因此可以通过规则公式来计算迁移块的地址,不需要额外的映射表。
Power Control Policy
首先使用了 ARMAX 模型来预测工作负载,得到下一个时间间隔内的平均请求到达率为
ARMAX 模型简介
AutoRegressive Moving Average with eXplanatory variable 模型是一种时间序列预测模型,用于描述和预测时间序列的特征值。该模型结合了自回归(AR)模型、滑动平均(MA)模型和外生变量(X)的影响。ARMAX 模型可以表示为:
之后设计一个粗略的性能模型,假定每个请求访问给定磁盘的概率是 M/M/1 理论,计算每个磁盘的平均响应时间 t:
M/M/1 理论简介
M/M/1 理论是一种用于描述排队系统的数学模型。它指的是单个单服务器的排队系统,其中到达服务台的顾客遵循泊松到达过程,服务时间遵循指数分布。M/M/1 代表了三个参数:M 表示到达顾客的过程是泊松过程,即到达的顾客间隔时间是指数分布的;M 表示服务时间是指数分布的,即顾客的服务时间是随机的且满足整个服务过程内的完全独立性;表示只有一个服务台(服务器),顾客到达后会立即被服务,不会有其他服务器来帮助服务。
M/M/1 理论可以帮助我们分析排队系统的性能指标,如平均等待时间、系统均衡度等。它对于优化服务台资源的利用、提高系统效率以及预测系统的性能表现都有重要的参考价值。M/M/1理论中的平均逗留时间(Average Residency Time)可以通过以下公式计算:
其中,
最后将平均响应时 t 与限制的平均响应时间

Data Reorganization
ES 数据迁移算法。迁移的目标是将部分工作负载转移到待启动磁盘上,提高性能,需要满足的条件包括:只有相对少量的数据被移动;需要平衡数据迁移后所有活动磁盘之间的工作负载;不要引入条带退化。为了减少数据迁移量,将优先迁移相对热度更高的数据,因为根据现有研究表明,只有少量数据被频繁访问,而大量数据很少被访问。文中将数据热度定义为:在给定的时间段内访问数据的次数。根据时间局部性,在下一时间段不会发生太大变化。以下公式计算阈值
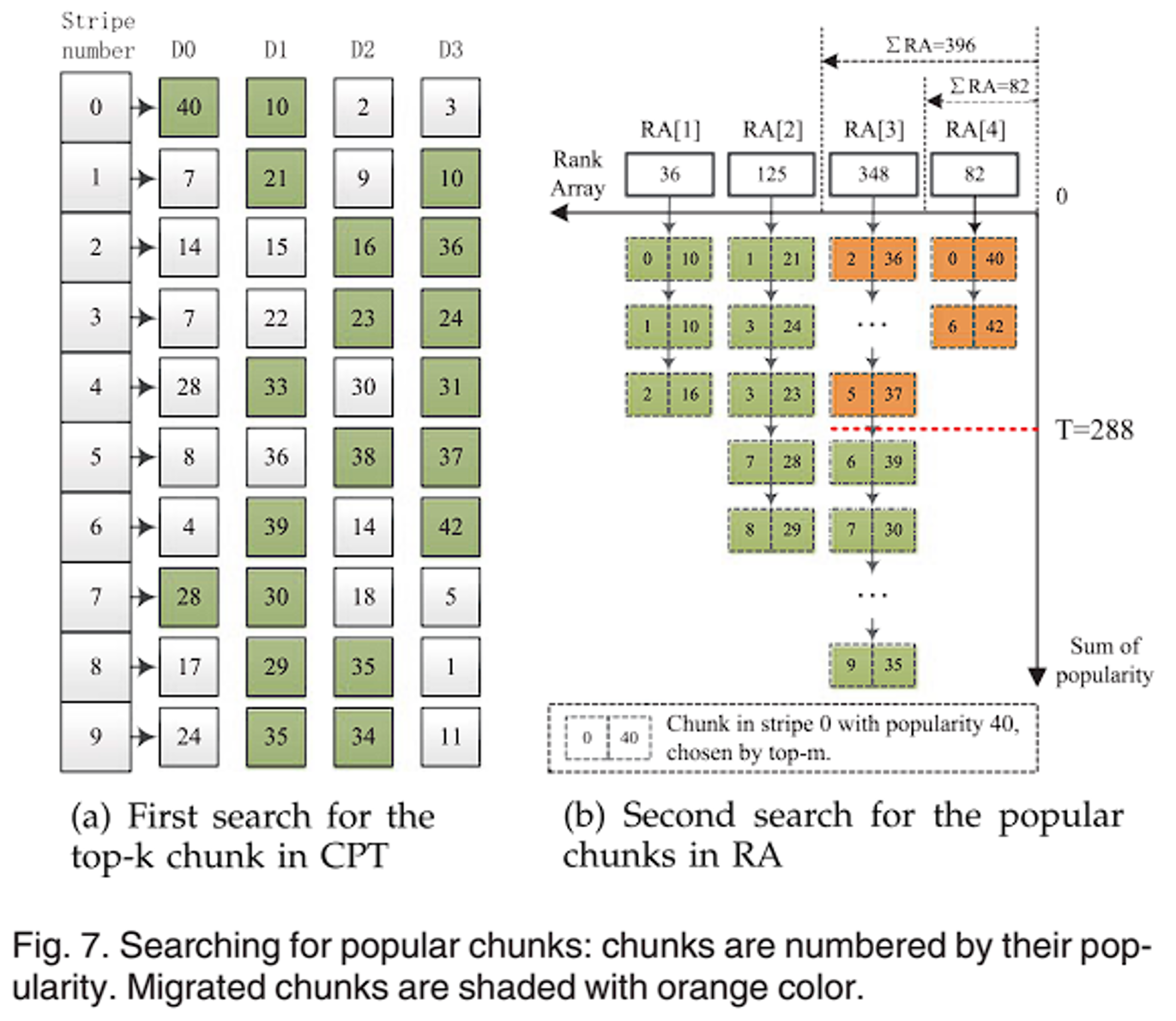
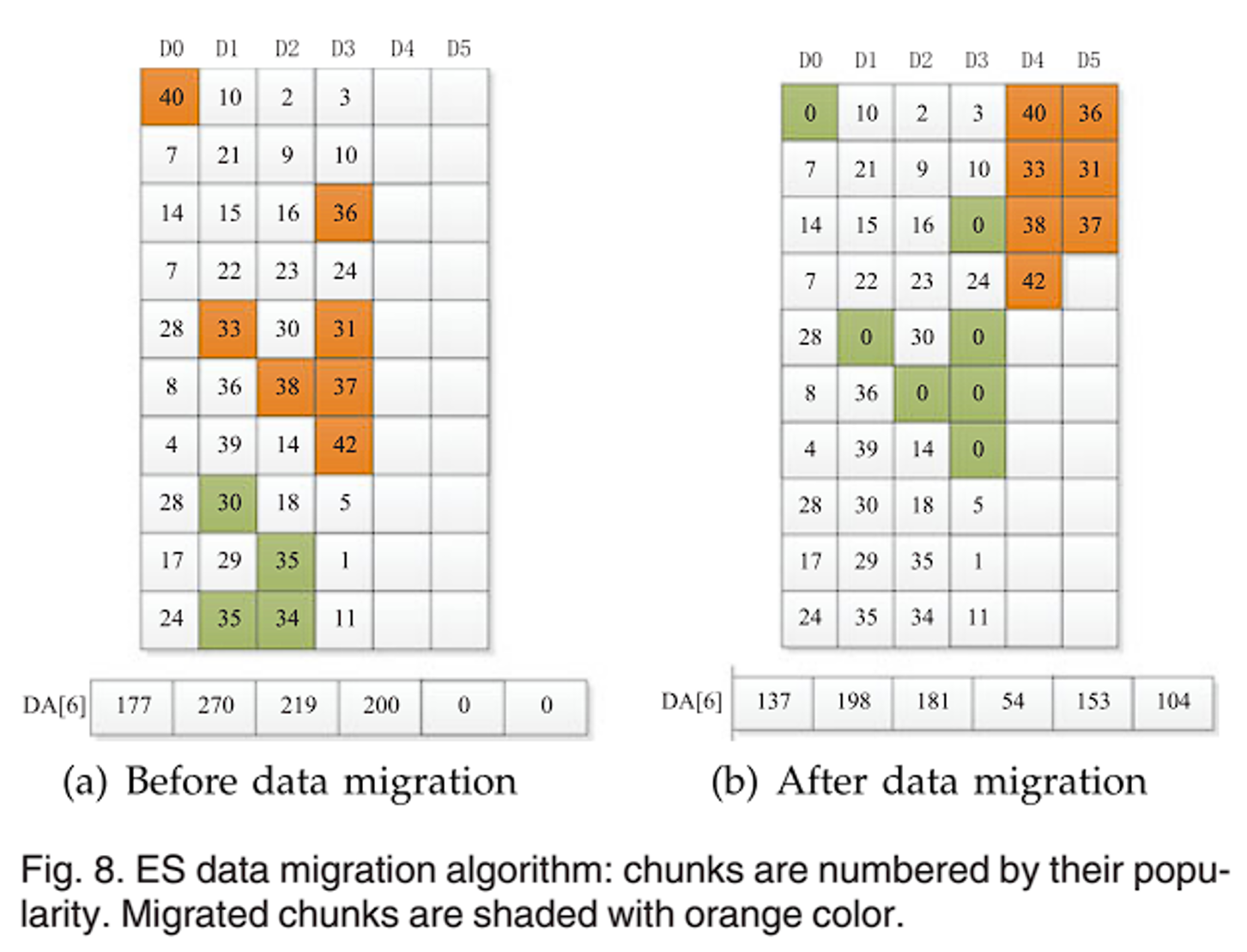
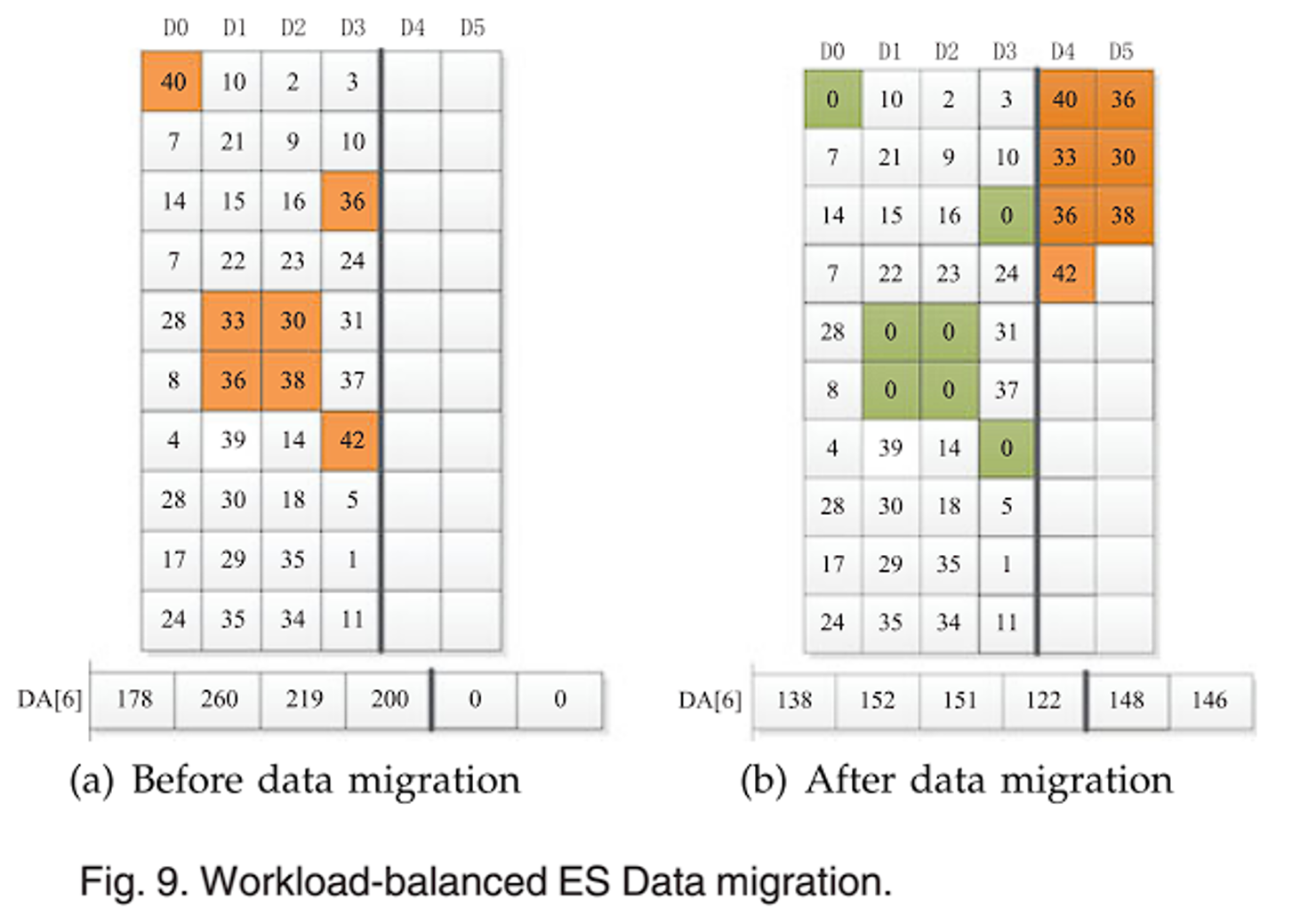
CPT 表中列了每个条带每个数据块的热度值。K=2,有 2 个待启动磁盘。因此如图 a,首先查找 CPT 表,找到每个条带中热度最高的 2 个块,以绿色标明;然后将这些块以热度为标准进行分级,比如热度为 40,取他的十位数 4,因此归为 RA[4] 中;热度为 10,归为 RA[1] 中,之后计算每个 RA 区间的热度之和,存放在数组中,如图 b;通过上一步的能源控制策略计算阈值 T=288,之后从高阶到低阶查找块,也就是以右上角为原点,建立图 b 这样的坐标系,从右上的高阶往左下找,直到已查找的黄色块的热度之和将要超过阈值 T,而包括下一块的热度之和大于阈值 T;这些块就是需要迁移到待启动磁盘上的数据块,如图 8a,8b。最后需要平衡工作负载,也就是让各个磁盘的热度保持平衡,也就是热度差异不大,如图 8b,下面的 DA 数组保存了各个磁盘的热度,可以发现磁盘 D3 的热度明显小于其他磁盘,因此将其中部分数据块进行替代,也就是对比图 8b,图 9a,将 31 替换为 30,将 37 替换为 36。最终得到的平衡工作负载后的数据迁移结果如图 9b。
ThinRAID 架构
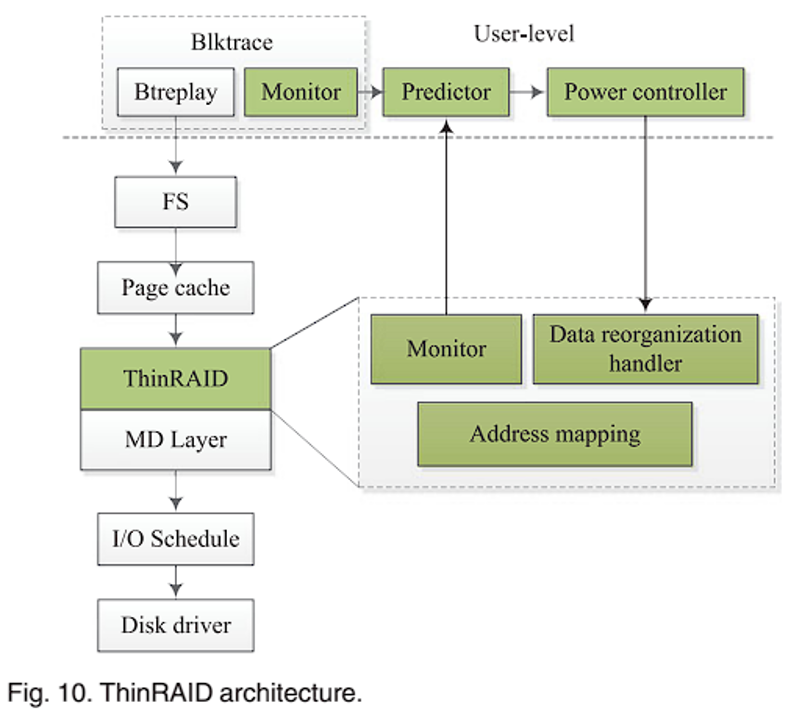
ThinRAID 在 Linux 上实现原型,用多个磁盘构建软件 RAID(软件 RAID,也称为操作系统级 RAID,是一种通过操作系统提供的软件实现的 RAID 技术。它使用操作系统的软件来管理多个磁盘驱动器,将它们组合成一个逻辑存储设备,提供数据的冗余性和性能。软件RAID不依赖于特殊的RAID控制器硬件,而是在操作系统内核中实现RAID的功能),ThinRAID 由运行在 User-level 的用户级监视器、预测器、功率控制器和运行在 Kernel-level 的内核级监视器、数据重组处理器和地址映射 6 个模块组成。blktrace 直接向块层发出请求,用户级监视器记录 blktrace 发出的 I/O 请求,I/O 信息收集并发送给 Predictor;Predictor 从监视器获得的 I/O 信息作为输入,并预测下一个时间间隔的工作负载;Power Controller 根据预测的工作负载和设定的平均响应时间限制
实验评估
之后是实验部分(首先评估了 ThinRAID 和 RAID-5 的能耗,然后比较了它们之间的性能;为了评估不同的布局及其对节能和性能的影响,我们将 ThinRAID 与 PARAID 进行了比较。最后,评估了迁移算法和预测模块的影响)。
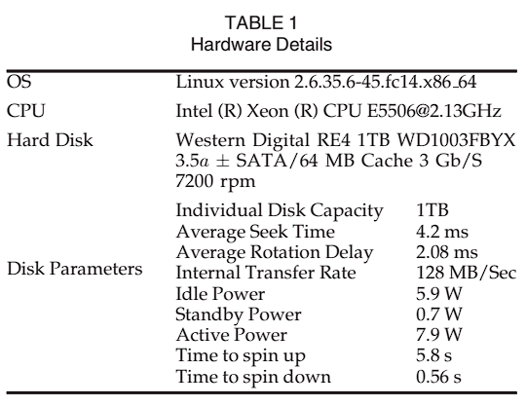
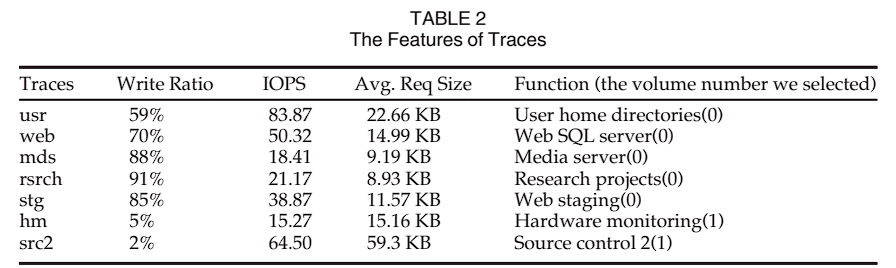
表 1 是实验的硬件参数,使用 6 个磁盘,4 个活动磁盘和 2 个休眠磁盘,4 个活动磁盘是低功耗,6 个活动磁盘是高功耗。设定
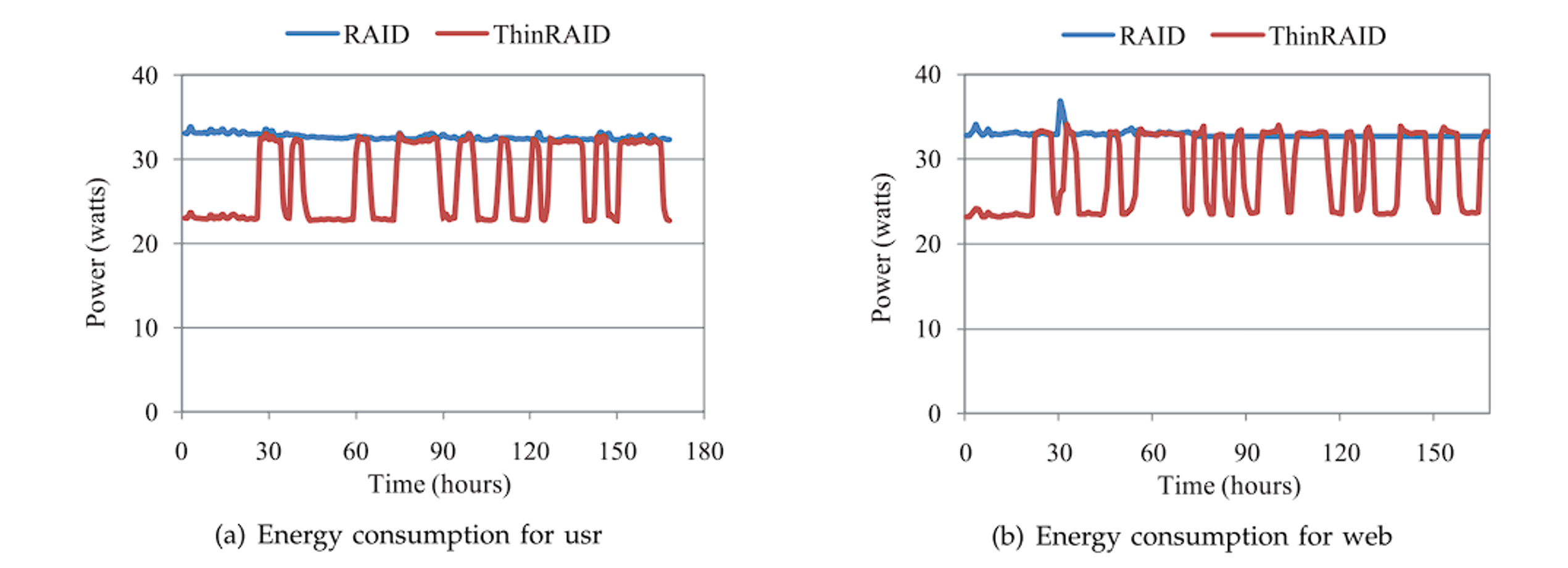
图 12a 和图 12b 分别是 ThinRAID 和 RAID5 在两种工作负载下的功耗对比图:ThinRAID 可以快速在低功耗和高功耗模式之间切换,低功耗模式时,可以节能约 30%。
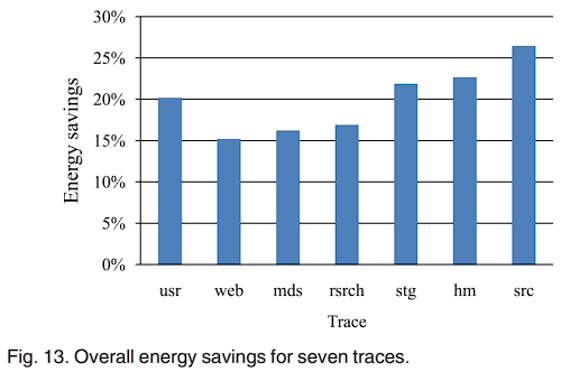
图 13 显示了 7 个 traces 下与 RAID-5 功耗的比较。ThinRAID 可以在各种 traces 下提供 15%-27% 的节能,其中 web trace 下节能最少,因为 web 条件下需要处理更多的 I/O,工作负载高,且由表 3 可以看出 web 的模式切换次数最多,低功耗的时间最少。
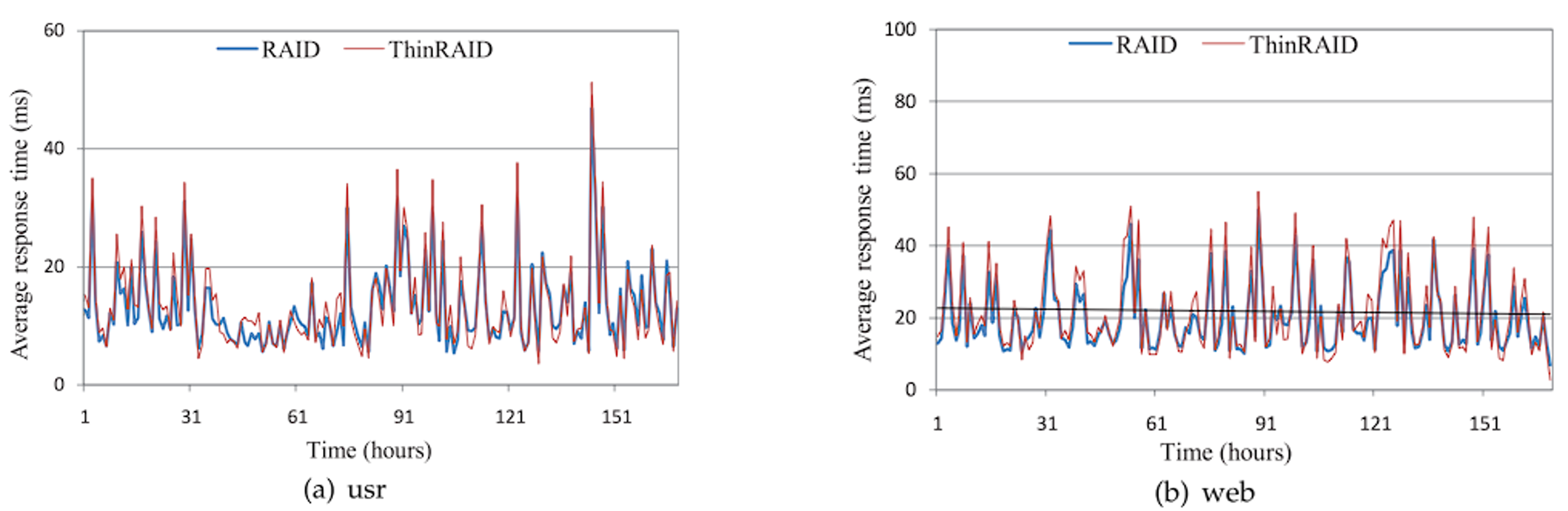
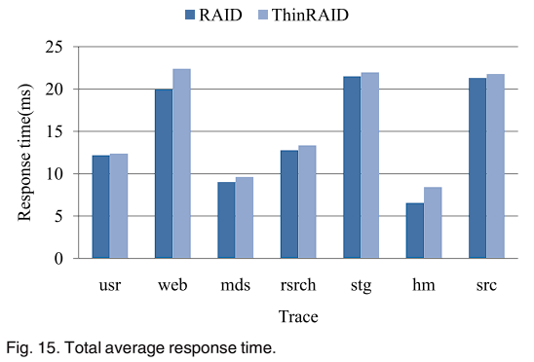
然后是性能影响。图 14 比较了 ThinRAID 和 RAID-5 两种 traces 下的平均响应时间。ThinRAID 的平均响应时间都比 RAID-5 略高,因为 ThinRAID 在低功耗模式下只将工作负载分布在 4 个磁盘上;有时 ThinRAID 的响应时间比 RAID-5 低,因为迁移到待启动磁盘上的少量数据分布比较靠近且集中,减少了寻道时间,并且高功耗模式下,磁盘并行性与 RAID-5 相同;图 15,对于每个 trace,RAID-5 在响应时间方面略优于 ThinRAID,原因在于功耗模式的切换,低功耗模式下 ThinRAID 的磁盘并行性低于 RAID-5;在 web trace 下差距最大,因为 web 有更多负载峰值,功耗模式切换最频繁,导致 web 预测精度最低,性能下降较大。
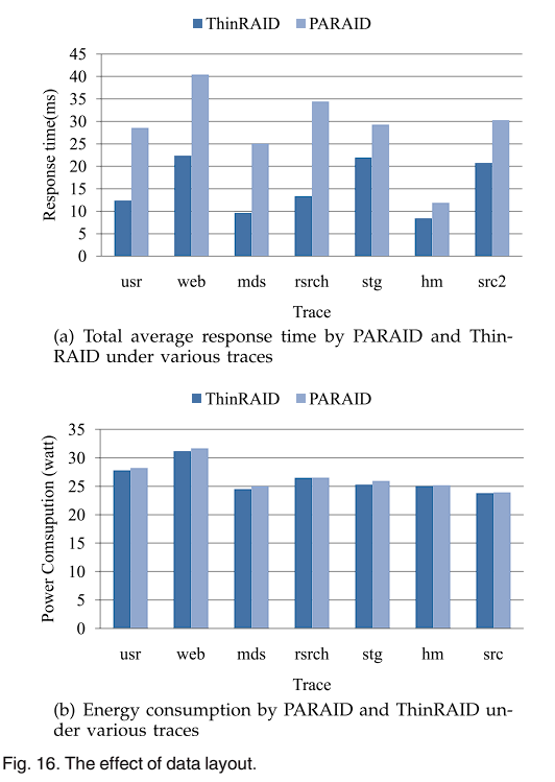
之后是数据布局的影响。如图 16a,平均响应时间上 ThinRAID 比 PARAID 性能有大幅提高达 25-62%;如图 16b,ThinRAID 节能效果略好于 PARAID,主要原因是 PARAID 的条带退化增加了磁头的移动距离,且 PARAID 中的奇偶校验更新会产生大量额外开销。
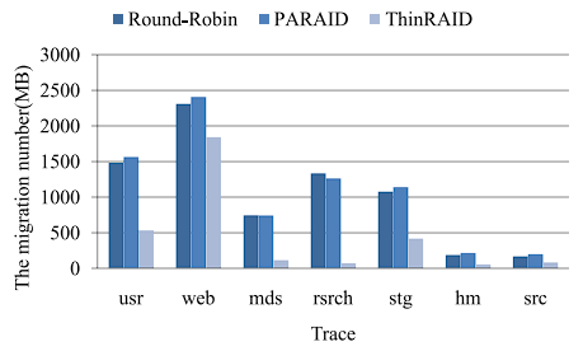
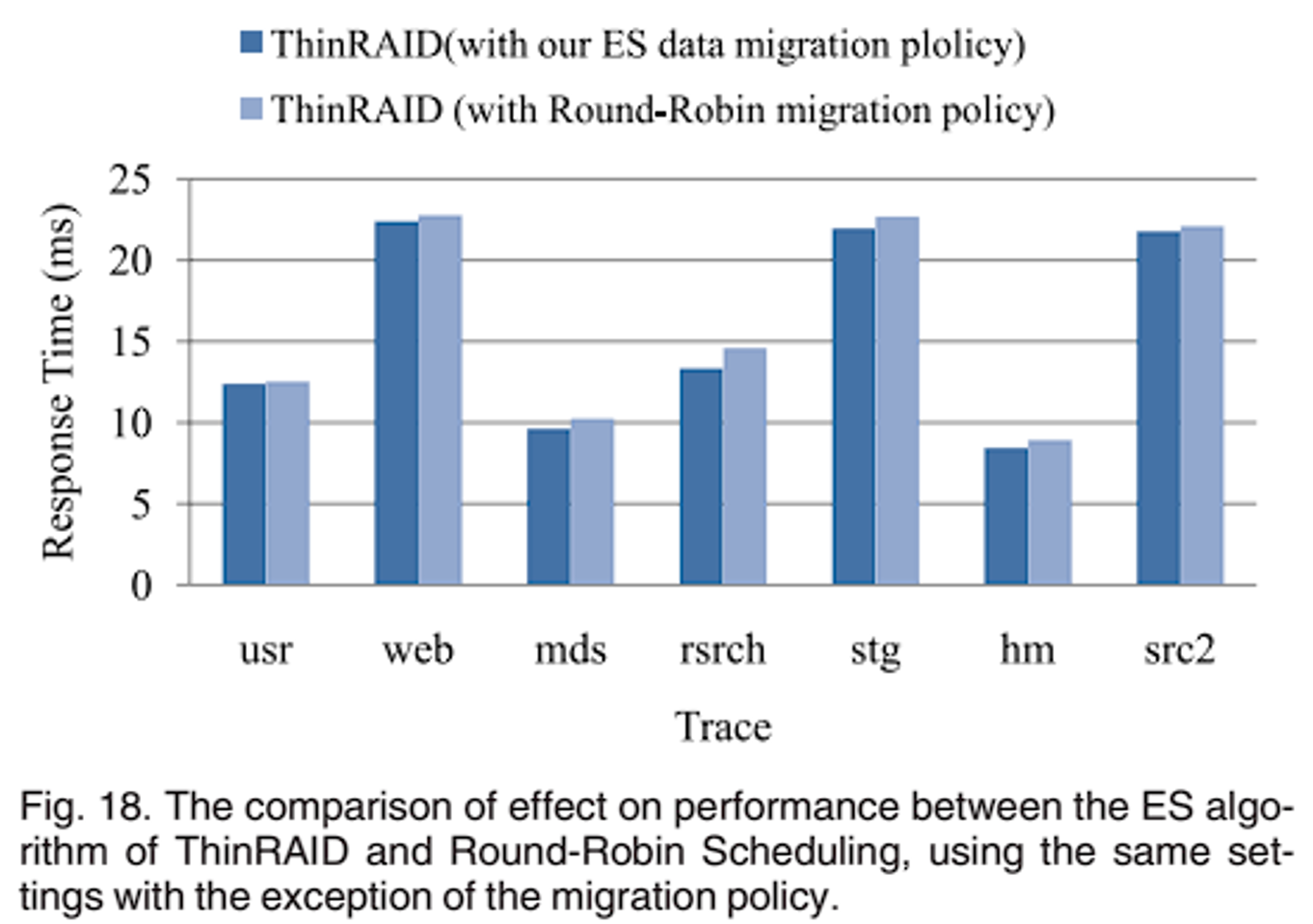
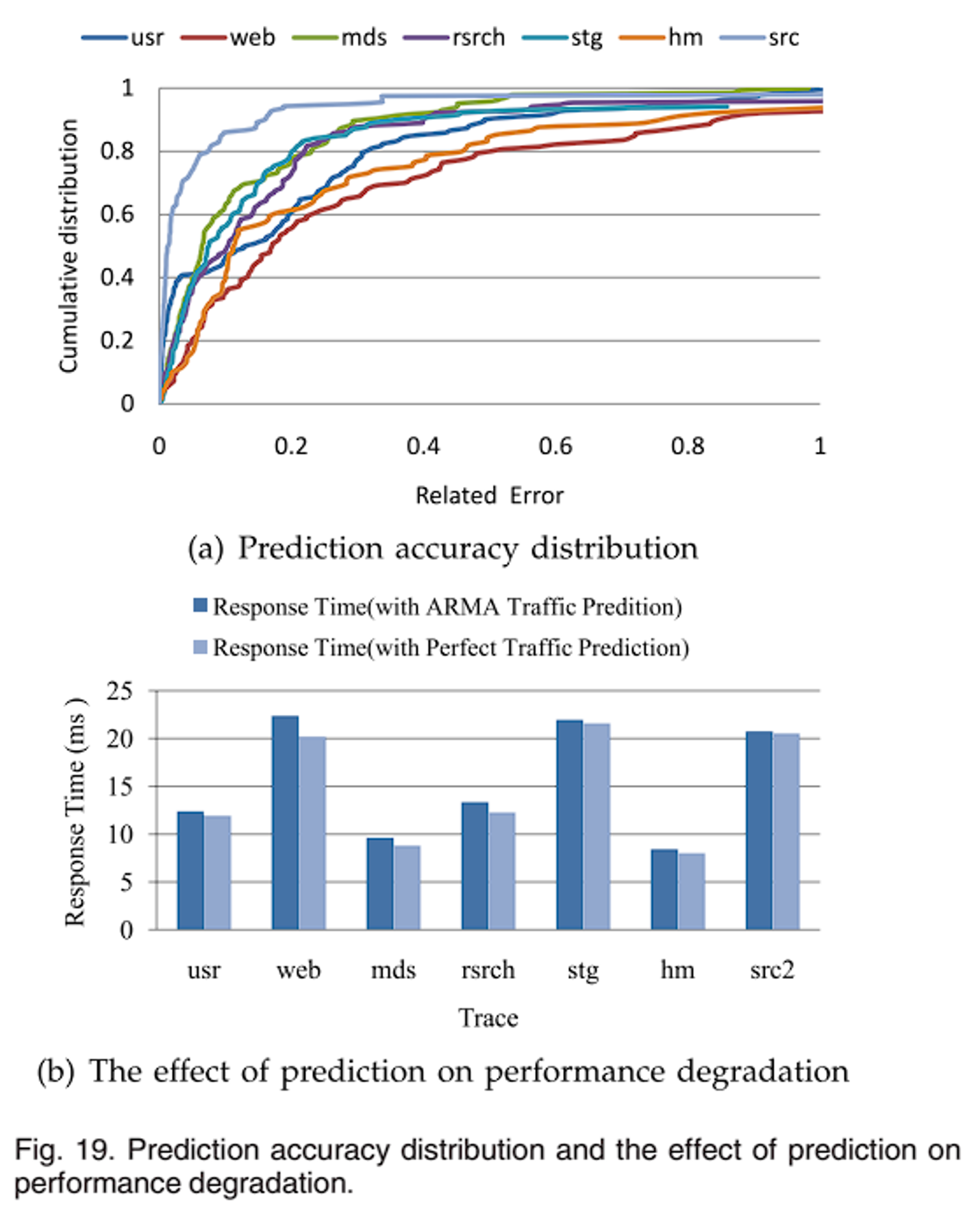
在迁移算法的影响上,评估了三种方案:PARAID 的迁移策略、Round Robin 调度迁移和本文 ES 迁移算法。PARAID 迁移策略,将带关闭磁盘中的所有数据迁移到活动磁盘的空闲空间,然后只有修改过的块才会被写回;对于Round Robin 调度中迁移的块是按照条带数量的递增顺序和磁盘数量的循环顺序选择。例如,如果我们在系统中使用 N 个磁盘,那么我们期望选择的第 i 个区块位于第 i 个条带和第 j 个(j = i mod N)磁盘上。如图 17 所示,与其他两个方案相比,ES 迁移算法迁移的块更少;如图 18,将 ThinRAID 迁移策略分别设置为 ES 迁移算法和 Round-Robin 调度算法,ES 数据迁移算法在大多数 traces 下性能较好,因为在 ES 迁移算法中迁移的数据在待启动磁盘上分布集中且靠近,减少了寻道时间。最后是预测的影响。图 19a 显示了七个工作负载下的预测准确性。大约 90% 的情况下,预测误差小于 1,70% 小于 0.3。结合图 19a 和表 3,预测精度的高低与功耗模式切换次数大致成反比,次数越多,预测精度越低,说明 I/O 请求分布越平稳,预测精度越高。预测误差对性能的影响如图 19b,说明了预测精度对性能下降的影响不大,其中 web 负载影响最大,原因在于存在很多负载峰值,切换功耗模式频繁,导致预测不准确。
总结
本文工作是针对数据中心的能源消耗问题,根据数据集大小使用部分磁盘建立 RAID 以节省能源,核心思路是建立模型对工作负载进行预测确定待启动磁盘个数,优先迁移高热度数据至待启动磁盘减少迁移开销,最后替换部分数据块以平衡活动磁盘工作负载。未提及的点我认为有 Power Control Policy 中的粗略性能模型条件设置为理想情况,未考虑影响因素(比如到达率大于等于服务率,则不能计算);未给出限制平均响应时间