
了解 SPDK。
简介
SPDK 存储性能开发套件(Storage Performance Development Kit)—— 针对于支持 NVMe 协议的 SSD 设备。
是 Intel 发布的,提供了一整套工具和库,以实现高性能、扩展性强、全用户态的存储应用程序。它是继 DPDK 之后,Intel 在存储领域推出的又一项颠覆性技术,旨在大幅缩减存储 I/O 栈的软件开销,从而提升存储性能,可以说它就是为了存储性能而生。
SPDK 的基础是用户态、轮询、异步、无锁 NVMe 驱动。这提供了从用户空间应用程序直接访问 SSD 的零拷贝、高度并行的访问。
SPDK 引入目的和优势
详见:为什么用 SPDK?
总结版:
| 传统 I/O | SPDK |
|---|---|
| 以前的 I/O 栈针对 HDD 做了诸多优化:page cache等;内核采用中断方式进行 DMA; | 这样的优化会使 SSD 存在空缺,不能充分利用。 |
| 会存在大量的内核上下文切换和中断,造成大量的延迟和开销。 | SPDK 采用将设备驱动代码放在用户态(userspace I/O),避免内核上下文切换。spdk 采用轮询(polling)模式代替。 |
| 应用程序提交读写请求后进入睡眠状态,一旦 I/O 完成,中断就会将其唤醒。 | 应用程序提交读写请求后继续执行其他工作,以一定的时间间隔回头检查 I/O 是否已经完成。(因为 SSD 很快,传统方式会导致 “请求后进入睡眠再醒来过程太慢”) |
| 中断开销只占整个 I/O 时间(I/O 读取慢)的很小的百分比,因此给系统带来了巨大的效率提升。 | 持续引入更低时延的持久化设备,I/O 读取变快,中断开销成为了整个 I/O 时间中不可忽视的部分。所以需要去优化,使其达到平衡。 |
SPDK 关键技术
将所有必要的驱动程序移动到用户空间,从而避免 syscalls,并允许可以直接使用用户态内存落盘实现零拷贝。
- 对硬件进行完成轮询,而不是依赖中断,降低了总延迟。
- 任何业务都可以在 spdk 的线程中将轮询函数注册为 poller,注册之后该函数会在 spdk 中周期性的执行,避免了 epoll 等事件通知机制造成的 overhead。
- 避免 I/O 路径中的所有锁,使用无锁队列传递消息 I/O。
- 为了降低这种性能开销,spdk 引入了无锁队列,使用 lock-free 编程,从而避免锁带来的性能损耗。
- spdk 的无锁队列主要依赖的 dpdk 的实现,其本质是使用 cas(compare and swap)实现了多生产者多消费者 FIFO 队列。
SPDK 主要运用了两项关键技术:用户态 I/O(UI/O)和轮询(polling)。
因此 SPDK 的实施目标就是:要在用户态实施一套基于用户态软件驱动的完整 I/O 栈,避免在 spdk 核上出现进程上下文切换。
SPDK 软件架构
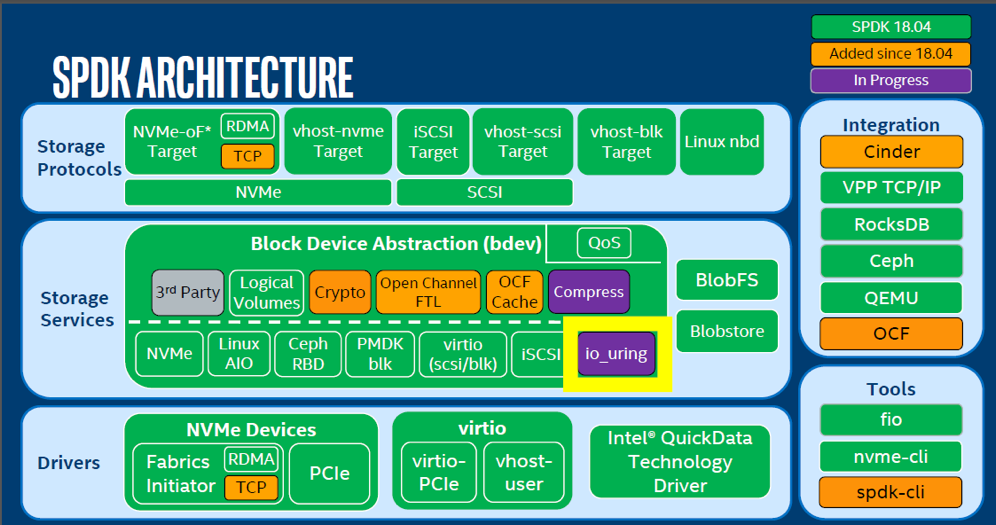
底层:驱动层(Drivers)
包括:NVMe PCIe 驱动,以及 NVMe-oF 驱动。
中间层:存储服务层(Storage Services)
核心是提供了一个块设备抽象层,并实现了块设备的常见功能如逻辑卷、快照、克隆。
bdev 的 API 与 Linux 文件系统的 API 非常类似,主要是打开关闭设备和进行数据读写等功能。
上层:存储协议层(Storage Protocols)
通过存储协议访问 NVMe 提供的存储功能。
SPDK 项目结构
./app(核心)
包含 build/bin/ 中应用程序的源代码,可以以这些应用程序的源代码 ./app/* 作为切入点学习 SPDK 的使用和实现。
./lib(核心)
核心功能,以库的形式提供,如事件、线程模型等。
./module(核心)
实现中间层存储服务层相关的功能。
./examples
包含一些使用参考,可以进行学习,如 examples/nvme/hello_world。
./scripts
包含一些 sh 脚本,方便一些操作。如 ./scripts/setup.sh 用于从内核驱动中绑定和取消绑定设备;./scripts/pkgdep.sh 用于安装依赖。
./tests
测试文件,单元测试、函数功能测试。
SPDK hello_world 示例分析
源代码位于 examples/nvme/hello_world 下,可执行文件位于 build/examples/hello_world 下。通过 hello_world 入门 SPDK 的运行流程,了解 SPDK 用户态驱动的主要工作流程和方式。