修改 perf 中的监控功能,进行功能测试,分析存在的问题。
环境准备
- Ubuntu 22.04 虚拟机 x4
- dev1,作为 Host 端,ip:192.168.246.129
- dev2,作为 Target0,ip:192.168.246.130
- dev3,作为 Target1,ip:192.168.246.131
- dev4,作为 Target2,ip:192.168.246.132
- 8 块虚拟硬盘:
- SATA x4:用于安装 Ubuntu
- NVMe x4:用于绑定 SPDK
perf 同时测试多个 Target、设置指定数目 QP
建立环境的操作见 【学习笔记】SPDK(二):SPDK NVMe over RDMA 部署。
Host 端:
1 | ./build/bin/spdk_nvme_perf -r 'trtype:rdma adrfam:IPv4 traddr:192.168.246.130 trsvcid:4420' -r 'trtype:rdma adrfam:IPv4 traddr:192.168.246.131 trsvcid:4420' -r 'trtype:rdma adrfam:IPv4 traddr:192.168.246.132 trsvcid:4420' -q 256 -o 4096 -w randrw -M 50 -t 5 -P 1 -G -LL -l --transport-stats |
每个 QP 映射一个 Target
本身就是,每个 NS 建立 1 个 QP,而每个 Target 只有 1 个 NS。
perf 当前 IO 任务下发、回收逻辑
简洁版:
1 | /*** 下发 ***/ |
重要的点在于如果没有超过时间,接收到的 req 对应的 task 会被重新利用,buffer 的地址不变、但 random offset 和 random read/write 的值会发生随机改变。
各层的 req 与 task 关联以及互相关联
请求之间转换关系图:
![]()
疑问:
wc->wr_id字段是如何赋值的?send_wr->imm_data、wc->imm_data如何使用?rsp->cpl字段是如何赋值的?
修改 perf IO 任务逻辑 - 初版
需要考虑兼容单 worker 和多 worker 的情形。
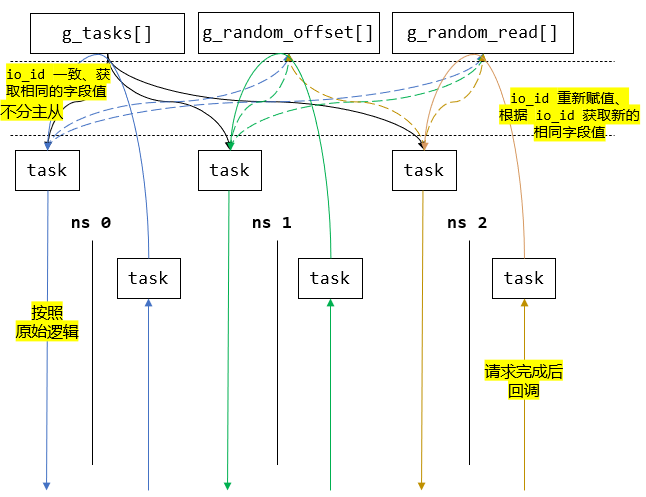
同一个 IO 任务复制多份
为
perf_task添加索引序号io_id字段;由
main_worker创建g_queue_depth个tasks,每个task中关联的ns_ctx指针暂时指向某个ns_ctx;这些
tasks保存在g_tasks指针数组中,这样所有worker_thread (ns)都可以通过复制得到相同的task;在分发
task时,需要深拷贝一份新的task然后修改关联的ns_ctx、iovs等指针。
task 一致性
由 perf 下发和回收逻辑看出,下发到多个 qpairs 的 task 之间,会发生改变的主要是 task->io_id、task->iovs (buffer)、task->md_iovs、offset_in_ios、task->is_read 等字段和变量。因此控制当 task->io_id 相等时,其他的字段和变量也对应一致就可以满足 task 复制的要求。
不需要要求多个 IO 同时发送,因此可以采取任务队列的类似思路。
- 由
main_worker:- 创建
g_queue_depth个g_tasks; g_random_num = 2 * g_queue_depth;- 创建
g_random_num长度的g_offset_in_ios数组; - 创建
g_random_num长度的g_is_read数组。
- 创建
提前通过
srand(time(NULL))和rand()初始化好g_offset_in_ios和g_is_read;每提交一个
task时,从g_offset_in_ios和g_is_read中取出下标为task->io_id % (q_random_num)的随机值,这样就可以保证提交的下标相同的task的随机偏移量和r/w是一致的。
这样的思路理论上可以保证提交的下标相同的 task 的随机偏移量和 r/w 是一致的;而 task 的其他字段则在创建 g_tasks 时就已经配置好。
接收请求后重新利用 task 并提交
原 task 回收逻辑中,是将之前发送过的 task 重新利用,其中的字段都不变,仅修改 offset_in_ios 和 is_read 的值,然后创建新的 req。
多副本的情况下,需要保证 offset_in_ios 和 is_read 一致,同时能够跟踪到 task_io_id,所以修改的思路为:
task->io_id在每次收到后都+= g_queue_depth,这样不会导致task->io_id的重复(同一个ns提交多次task->io_id = n的请求);重新利用
task->io_id并提交时,会进入到nvme_submit_io()函数中,在这个函数里为offset_in_ios和is_read进行了赋值,修改为直接获取下标为task->io_id % (g_random_num)的已经保存在数组中的随机值。
多副本 IO 同步
暂未考虑。
多个 task 内存回收
在 cleanup 阶段统一清理 g_tasks 数组。
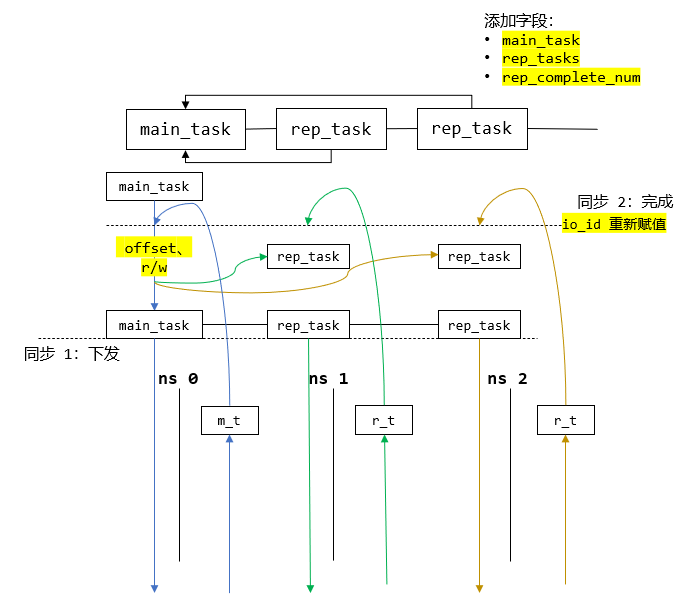
修改后 IO 任务下发、回收逻辑
简洁版图示:
修改 perf IO 任务逻辑 - 优化后
假设在单 worker 情形。
同一个 IO 任务复制多份
分主从副本
main_task和rep_task,其中main_task维护了一个副本队列,包括自己在内的所有副本;每个副本都有指向主副本
main_task的指针字段;每个
worker都可以感知到所有ns_ctx;worker遍历其所有ns_ctx,第一个对应的副本为主副本;当创建主副本后,其他的ns_ctx对应的副本都为从副本。
task 一致性
当主副本设置完 io 偏移量以及随机读写后,遍历其副本队列,同步给所有从副本;
然后执行提交 IO 任务的逻辑。
接收请求后重新利用 task 并提交
task->io_id在每次收到后都+= g_queue_depth,这样不会导致task->io_id的重复(同一个ns提交多次task->io_id = n的请求);重新利用
task->io_id并提交时,会进入到nvme_submit_io()函数中,在这个函数里为offset_in_ios和is_read进行了重新随机赋值,之后主副本再次同步给所有从副本。
多副本 IO 同步
存在两次同步:
下发同一个 IO 任务时,提交主副本。在主副本提交前遍历其副本队列,将他们都提交到相应 NS 的队列;
任务完成后,主副本的计数器满足要求才代表该 IO 任务完成。即当所有副本均完成后,该 IO 任务才算完成,然后才对主副本重新设置。
因此可能会造成某个 IO 任务的某个副本还没有完成,从而导致下一个 IO 无法下发的情况,但理论上这与实际不符。
多个 task 内存回收
达到运行时间后,回收主副本;
每个副本指向的
iovs内存地址只释放一次,而每个副本都要被回收释放。
修改后 IO 任务下发、回收逻辑
简洁版图示: