
NVMe 相关基础知识记录。
相关名词
SATA、PCIe
两者都是总线标准。
SATA 由 IDE/ATA 标准发展而来,主要用途是把存储设备连接到主板。
直连 PCI Express (PCIe) 总线的设计。端对端的互连协议,提供了高速传输带宽的解决方案。点对点的方式连接两个设备。
AHCI、NVMe
AHCI 和 NVMe 是逻辑(或者说软件、驱动程序)上的标准(协议)。
NVMe 只适用于 SSD(SSD 和主板也要支持 NVMe)。AHCI 则适用于机械硬盘和 SSD。
物理接口
- SATA 接口。采用这种接口的,只能使用 SATA 总线,不能使用 PCIe 总线。大部分 2.5”SSD 就是这种接口。
- M.2 接口。采用这种接口的 SSD,可以使用 SATA 或者 PCIe 总线(取决于主板和 SSD)。如果采用 PCIe 总线,又分为 AHCI 和 NVMe 两种协议。
- SATA Express 接口。SATA Express 使用的是 PCIe 总线,向下兼容 SATA 总线。
循环队列
SQ、CQ
SQ:Submission Queue,简称SQ。CQ:Completion Queue,简称CQ。
namespace
Host, Target 和 Transport
client 端称作 Host,处理 client 请求的部分称作 Target 端(连接物理 NVMe 设备),Host 和 Target 之间使用 NVMe 命令交流。Transport 是连接 Host 和 Target 的桥梁,可以是 RDMA 或者 FC。在 Fabrics 传输过程中,NVMe 命令会被相应的 Transport 代码封装(Capsule)和解析。
NVMe Subsystem, NVMe Namespace 和 Port
一个 Subsystem 就是一个 NVMe 子系统,Subsystem 在 target 端,Host 可以申请连接某个 target 的 Subsystem。一个 Port 代表一个 Transport 资源。Subsystem 必须和 Namespace,Port 建立关系,但是他们的联系又是很灵活的:即一个 Subsystem 可以包含多个 Namespace,一个 Namespace 可以加入多个 Subsystem,一个 Port 可以放入多个 Subsystem。
NVM Set 和 Endurance Group
NQN
NVM Qualified Name,用于唯一标识 NVMe 目标的名称格式,通常用于 iSCSI 和 Fabric 等协议中。
NQN 的主要特点: * 唯一性:NQN 通常是全局唯一的,确保在整个存储网络中可以唯一识别目标。 * 格式:NQN 的格式通常是 nqn.2021-09.io.spdk:nvm.target1,其中包含了时间戳和命名空间,这样可以避免名称冲突。 * 结构:NQN 的结构通常包括前缀、日期和描述符,以便于在组织中管理多个存储目标。 作用:
NQN 用于标识 NVMe 目标设备,以便在网络中进行连接和管理。它在存储网络中起到类似于 DNS 名称的作用,使得设备能够在网络上被识别和访问。
RDMA
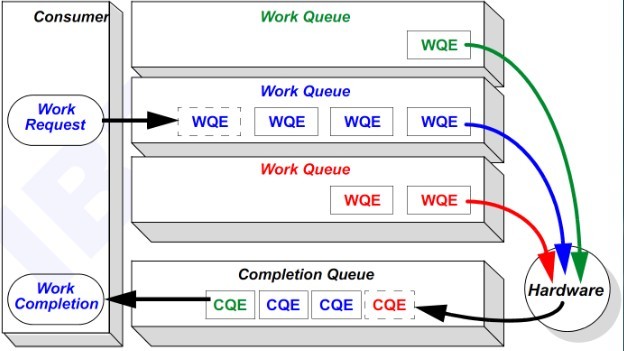
RDMA 操作可以简单理解为:
- Host 提交工作请求(WR)到工作队列(WQ):工作队列包括发送队列(SQ)和接收队列(RSQ)。工作队列的每一个元素叫做 WQE,也就是 WR。
- Host 从完成队列(CQ)中获取工作完成(WC):完成队列里的每一个元素叫做 CQE,也就是 WC。
- 具有 RDMA 引擎的硬件就是一个队列元素处理器。RDMA 硬件不断地从工作队列 WQ 中去取工作请求 WR 来执行,执行完了就给完成队列 CQ 中放置工作完成 WC。从生产者-消费者的角度理解就是:
- Host 生产 WR,把 WR 放到 WQ 中去
- RDMA 硬件消费 WR
- RDMA 硬件生产 WC,把 WC 放到 CQ 中去
- Host 消费 WC
NVMe
NVMe 是一种协议,而并非外形规格或接口规范。不同于其他存储协议,NVMe 将 SSD 设备视为内存,而不是硬盘驱动器。NVMe 协议的设计从一开始就以搭配 PCIe 接口使用为目标,因此几乎直接连接到服务器的 CPU 和内存子系统。
NVMe 旨在定义主机软件如何通过 PCI Express (PCIe) 总线与非易失性存储器进行通信,适用于各种 PCIe 固态硬盘 (SSD) 。
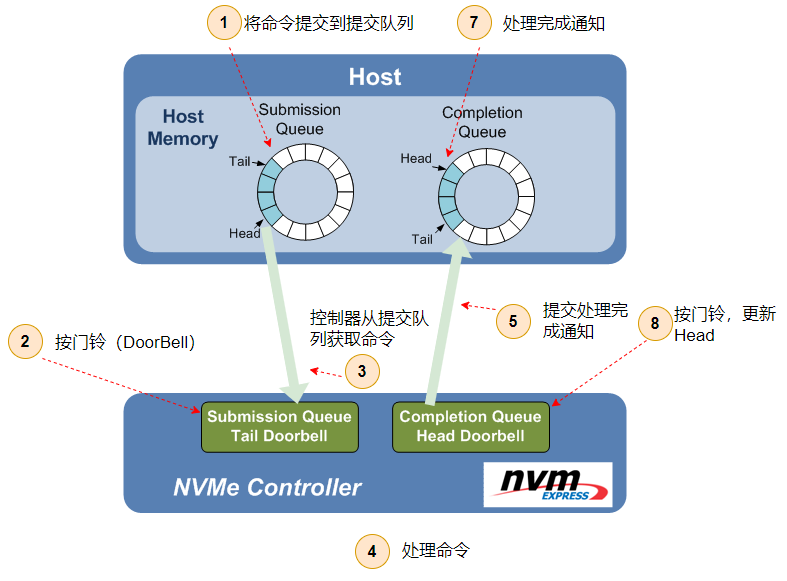
NVMe 中 Command 执行流程有 8 步,Host 与 Controller 之间用 PCIe TLP 传递信息。
Host 提交新的 Command。Host 下发一个新 Command 时,将其放入 Host 内存中 SQ。
Host 通知 Controller 提取 Command。Host 把 Command 写入 SQ 之后,此时 Device 并不知道这件事。所以,Host 此时需要给 Controller 发信息,通知 NVMe Controller。这个过程通过更新在 Controller 内部的寄存器 SQ Tail Doorbell 来完成。
NVMe Controller 从 SQ 提取 Command。取走 Command 之后,需要在 Controller 内部的 SQ Head Pointer 寄存器中更新 Head 所在的位置。NVMe 没有规定 Command 存入队列的执行顺序,Controller 可以一次取出多个 Command 进行批量处理。
NVMe Controller 执行从 SQ 提取的 Commands。一个队列中的 Command 执行顺序是不固定的(可能导致先提交的请求后处理),涉及到 NVMe 定义的命令仲裁机制。执行 Read/Wirte Command 时,这个过程也会与 Host Memory 进行数据传递。
NVMe Controller 将 Commands 的完成状态写入 CQ。此时,Controller 需要更新 CQ Tail Pointer 寄存器。
NVMe Controller 通知 Host 检查 Commands 的完成状态。Controller 通过发送一个中断信息告知 Host 已执行完毕。
Host 检查 CQ 中的 Completion 信息。
Host 告知 Controller 已处理完成 Completion 信息。此时,Host 更新 Controller 内部的 CQ Head Doorbell。告知 Controller 处理完毕。
流程示意图:
NVMe 相关规范
NVM-Express-Base-Specification-2.0b
NVM-Express-RDMA-Transport-Specification-1.0d
NVMe 技术概述
NVMe 队列管理
NVMe 命令仲裁机制
寻址模型 PRP 和 SGL
NVMe-oF
NVMe 协议并非局限于在服务器内部连接本地闪存驱动器,它还可通过网络使用。在网络环境内使用时,网络“架构”支持存储和服务器元素之间的任意连接。NVMe-oF 支持组织创建超高性能存储网络,其时延能够媲美直连存储。因而可在服务器之间按需共享快速存储设备。NVMe-oF 使用基于消息的模型通过网络在主机和目标存储设备之间发送请求和响应。
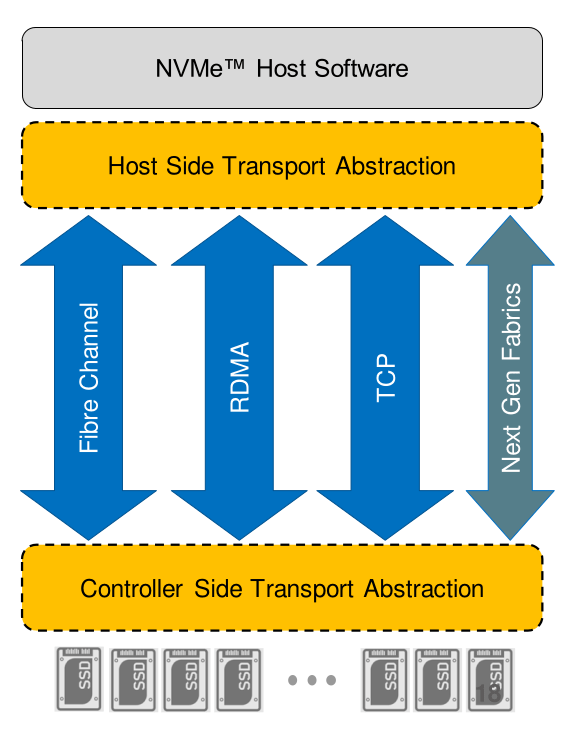
NVMe over TCP
基于现有的
IP网络,采用TCP协议传输NVMe,在网络基础设施不变的情况下实现端到端NVMe。NVMe over RDMA
RDMA是承载NoF的原生网络协议,RDMA协议除了RoCE外还包括IB(InfiniBand)和iWARP(Internet Wide Area RDMA Protocol)。NVMe over RDMA协议比较简单,直接把NVMe的IO队列映射到RDMA QP(Queue Pair)连接,通过RDMA SEND,RDMA WRITE,RDMA READ三个语义实现IO交互。
NVMe-oF 整体架构
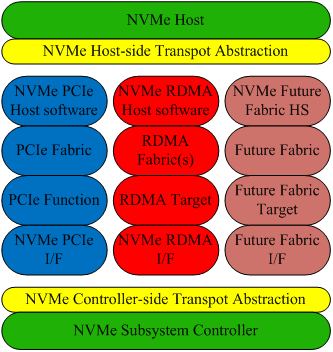
NVMe Host(Controller)-side Transport Abstraction 这两层便是 NVMe over Fabrics 协议的实现层。该协议只是一个用于 NVMe Transport 的抽象层而已,它并不实现真正的命令和数据传输功能,它只是为命令和数据传输定义了统一的规范,因此该协议只是“指导方针”。它是构建在 Fabrics 之上的,即它并不关心实际的 Fabrics 到底是什么,它只是提供了 Fabrics 通用的对接 NVMe 的接口,完成了对 NVMe 接口和命令在各种 Fabrics 而非只是 PCIe 上(NVMe Base 协议只涉及 PCIe 这一种 Fabric)的拓展。因此,为了使 NVMe 可以架构于不同的 Fabric 之上,各 Fabric 还需开发专用的功能实现层,真正实现基于此 Fabric 的数据传输功能,并完成和 Transport Abstraction 抽象层(即 NVMe over Fabrics 协议的实现层)的对接以使得传输抽象层可以调用到这些函数。
NVMe over RDMA
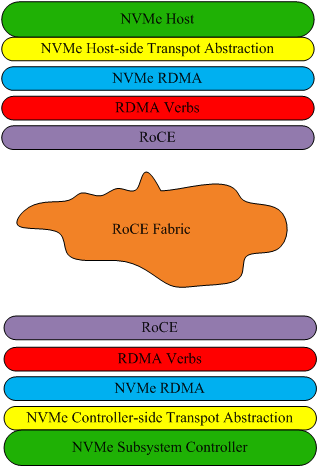
NVMe Host 和 NVMe Subsystem Controller 是 NVMe Base 协议扩展到 NVMe over Fabrics 的部分;NVMe Host(Controller)-side Transport Abstraction 则是 NVMe over Fabrics 传输抽象层的实现。RoCE 层则是支持 RoCE 技术的网卡及相关驱动和 RDMA 协议栈,而不论 InfiniBand、RoCE 或者 iWarp 何种具体的 RDMA 实现形式,都约定提供统一的操作接口,RDMA Verbs 便是 RDMA 技术向上层提供的接口。NVMe RDMA 则是实现将 RDMA 的接口 Verbs 和 NVMe 对接的关键粘合层,简言之,其作用是将 NVMe Transport Abstraction 传输抽象层提供的传输接口可以调用到下层 RDMA 提供的传输接口(即 verbs)。