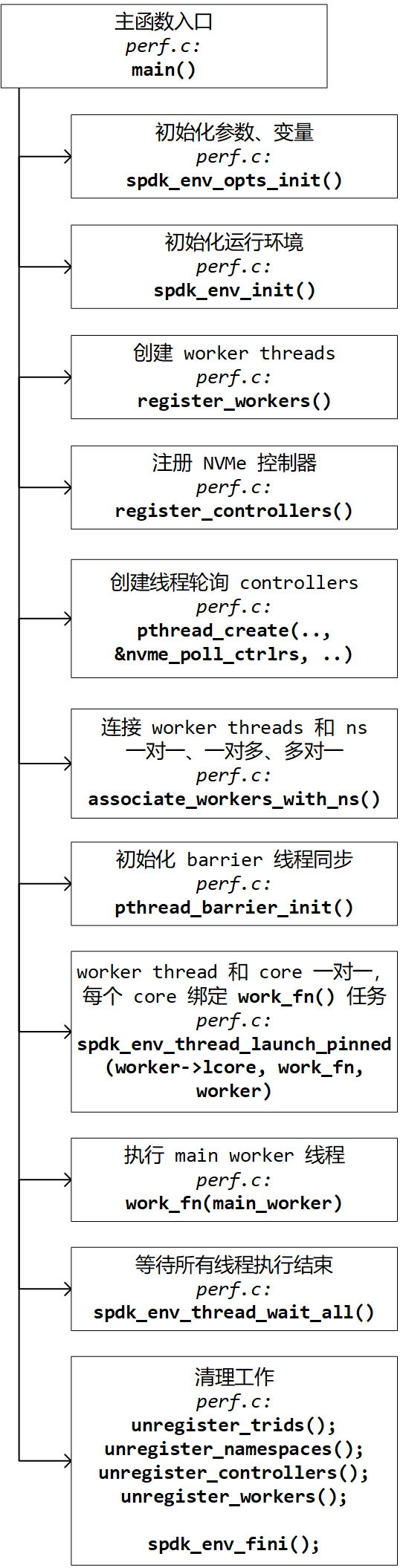
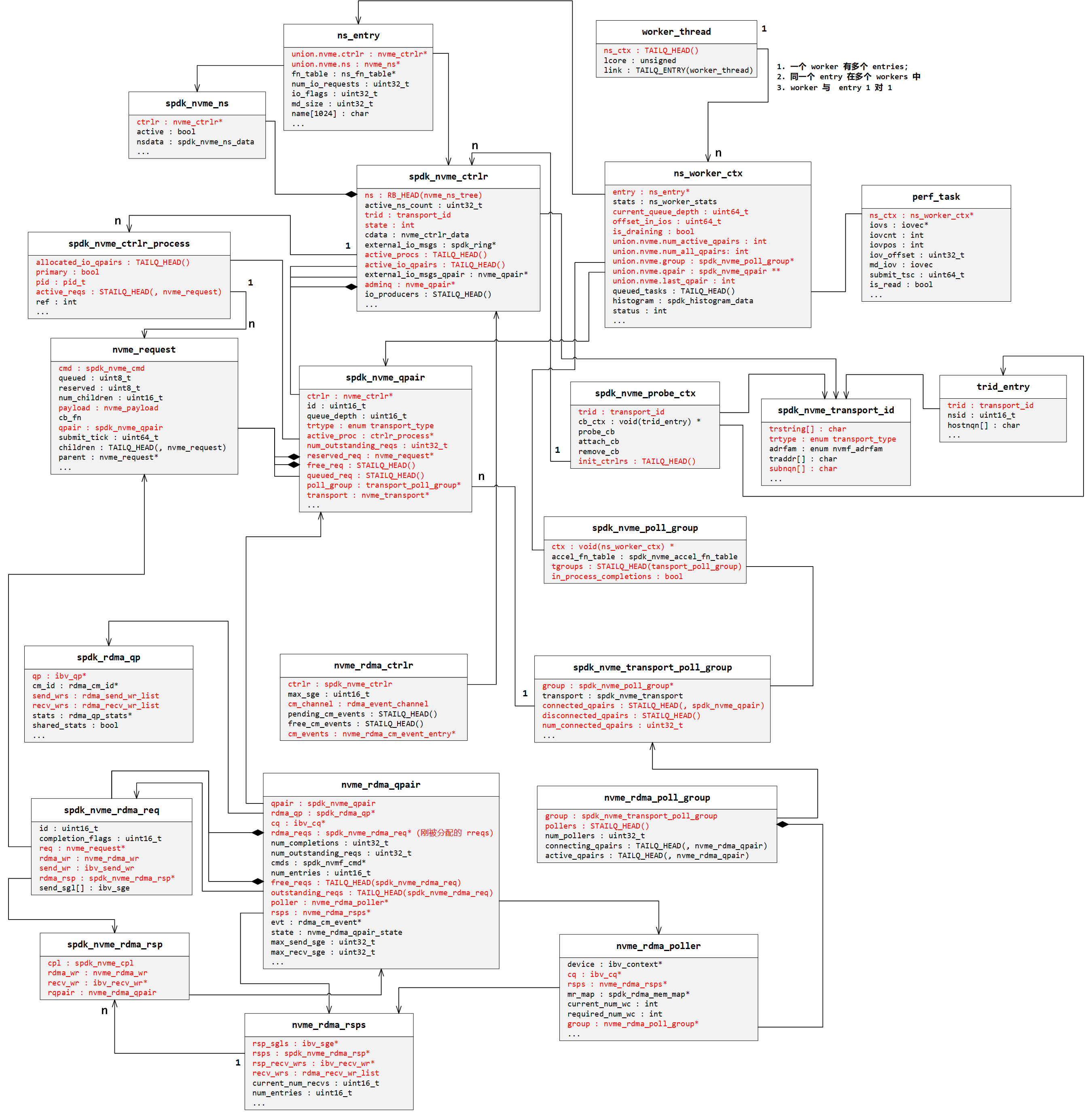
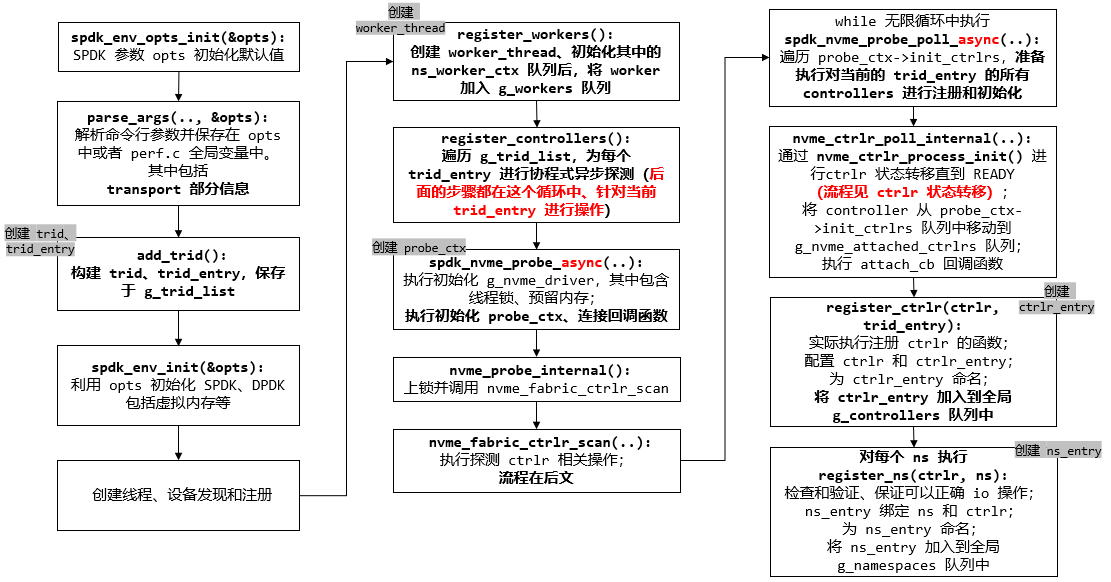
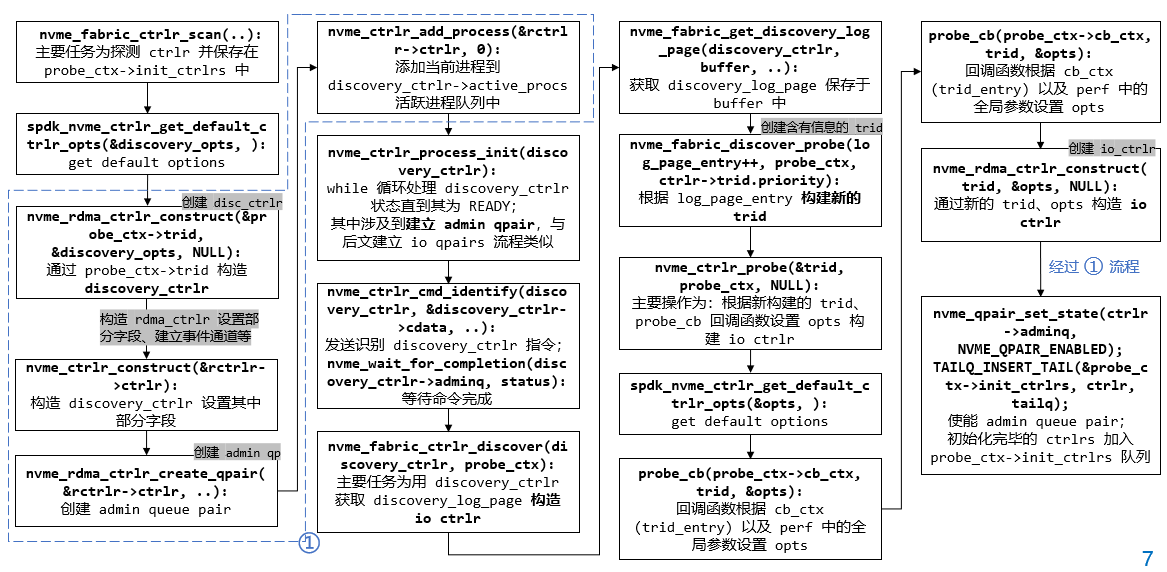
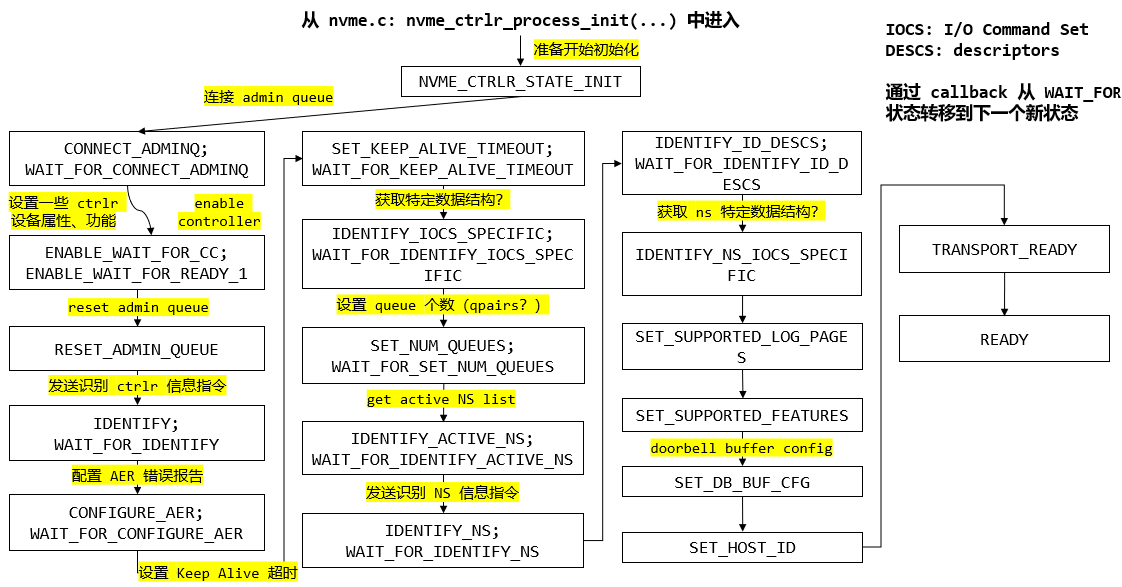
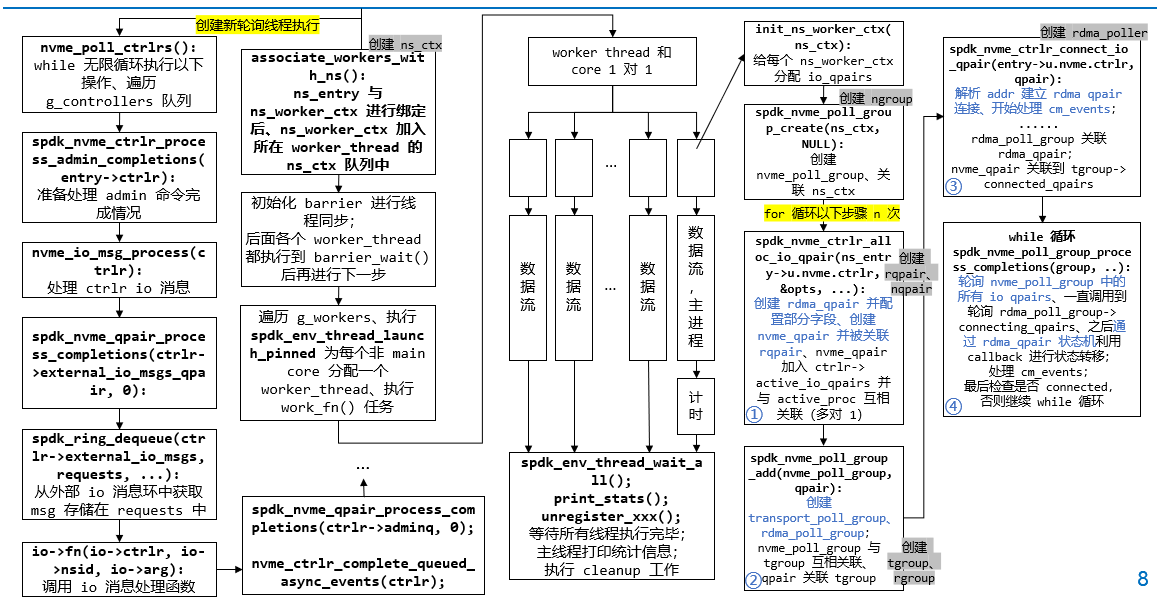
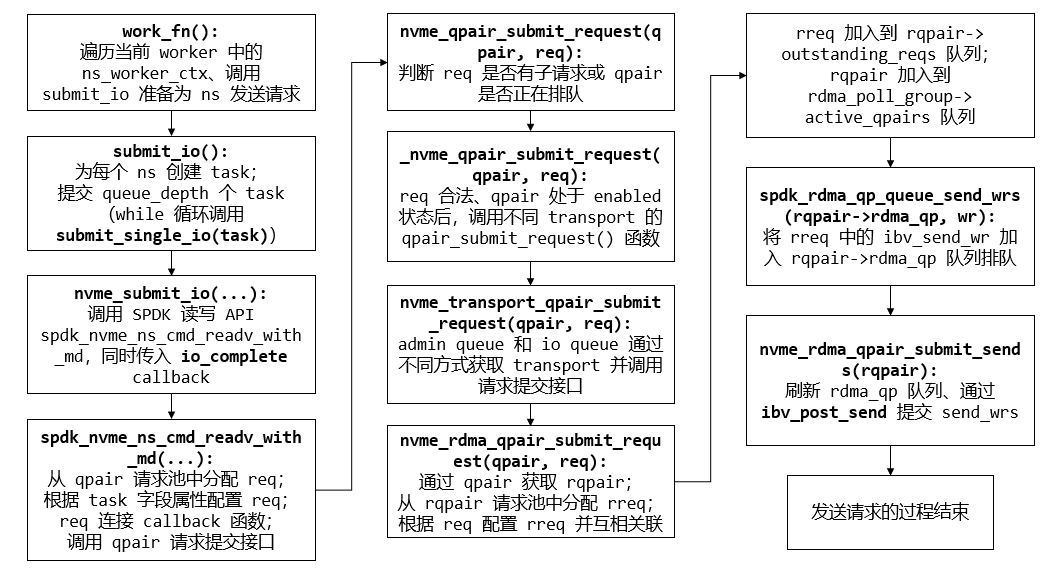
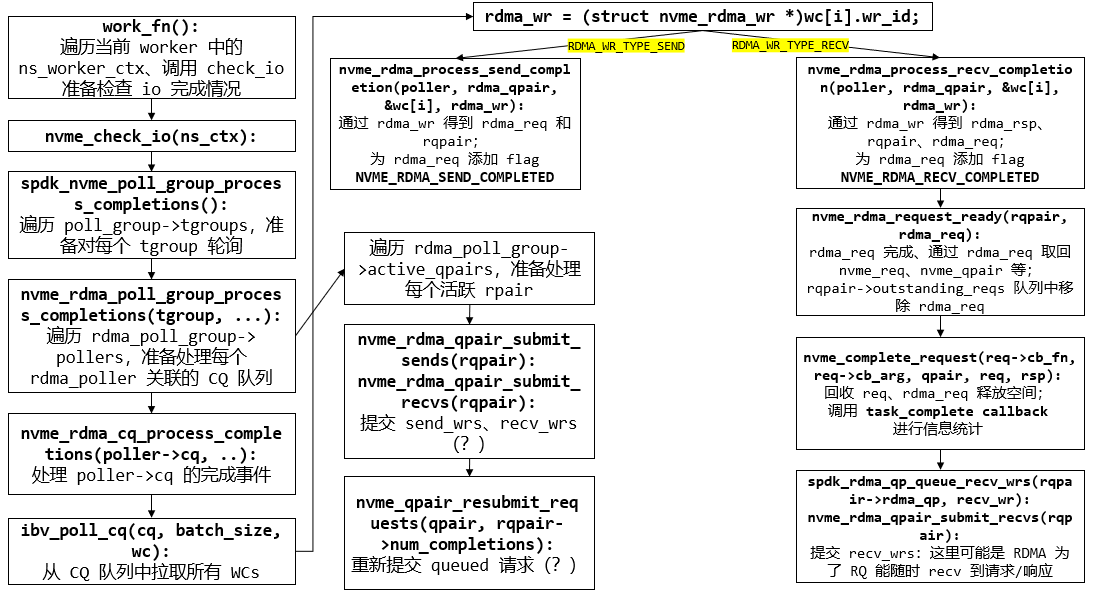
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
121
122
123
124
125
126
127
128
129
130
131
132
133
134
135
136
137
138
139
140
141
142
143
144
145
146
147
148
149
150
151
152
153
154
155
156
157
158
159
160
161
162
163
164
165
166
167
168
169
170
171
172
173
174
175
176
177
178
179
180
181
182
183
184
185
186
187
188
|
pthread_create(&thread_id, NULL, &nvme_poll_ctrlrs, NULL);
nvme_poll_ctrlrs():
while (true) {
foreach (entry, &g_controllers, link) {
spdk_nvme_ctrlr_process_admin_completions(entry->ctrlr):
nvme_ctrlr_keep_alive(ctrlr);
nvme_io_msg_process(ctrlr):
if (ctrlr->needs_io_msg_update): nvme_io_msg_ctrlr_update(ctrlr):
STAILQ_FOREACH(io_msg_producer, &ctrlr->io_producers, link) {
io_msg_producer->update(ctrlr);
}
spdk_nvme_qpair_process_completions(ctrlr->external_io_msgs_qpair, 0):
nvme_transport_qpair_process_completions(qpair, max_completions):
nvme_rdma_qpair_process_completions(qpair, max_completions):
TODO
count = spdk_ring_dequeue(ctrlr->external_io_msgs, requests, ...);
for (i < count) {
spdk_nvme_io_msg *io = requests[i];
io->fn(io->ctrlr, io->nsid, io->arg);
}
spdk_nvme_qpair_process_completions(ctrlr->adminq, 0):
nvme_transport_qpair_process_completions(qpair, max_completions):
nvme_rdma_qpair_process_completions(qpair, max_completions):
TODO
if (active_proc): nvme_ctrlr_complete_queued_async_events(ctrlr);
}
}
associate_workers_with_ns():
for (max(g_num_namespaces, g_num_workers)) {
allocate_ns_worker(ns_entry, worker):
ns_ctx->entry = entry;
TAILQ_INSERT_TAIL(&worker->ns_ctx, ns_ctx, link);
}
pthread_barrier_init(&g_worker_sync_barrier, NULL, g_num_workers);
TAILQ_FOREACH(worker, &g_workers, link) {
if (worker->lcore != g_main_core): spdk_env_thread_launch_pinned(worker->lcore, work_fn, worker);
}
work_fn(main_worker);
work_fn(worker):
TAILQ_FOREACH(ns_ctx, &worker->ns_ctx, link) {
nvme_init_ns_worker_ctx(ns_ctx):
spdk_nvme_ctrlr_get_default_io_qpair_opts(ns_entry->u.nvme.ctrlr, &opts, sizeof(opts));
ctrlr_opts = spdk_nvme_ctrlr_get_opts(ns_entry->u.nvme.ctrlr);
ns_ctx->u.nvme.group = spdk_nvme_poll_group_create(ns_ctx, NULL):
group->ctx = ns_ctx;
STAILQ_INIT(&group->tgroups);
for (i < ns_ctx->u.nvme.num_all_qpairs) {
ns_ctx->u.nvme.qpair[i] = spdk_nvme_ctrlr_alloc_io_qpair(ns_entry->u.nvme.ctrlr, &opts, ...):
qpair = nvme_ctrlr_create_io_qpair(ctrlr, &opts):
qid = spdk_nvme_ctrlr_alloc_qid(ctrlr);
qpair = nvme_rdma_ctrlr_create_io_qpair(ctrlr, qid, opts):
nvme_rdma_ctrlr_create_qpair(ctrlr, qid, ..., opts->async_mode = true):
rqpair->state = NVME_RDMA_QPAIR_STATE_INVALID;
qpair = &rqpair->qpair;
nvme_qpair_init(qpair, qid, ctrlr, qprio, num_requests, async):
...
qpair->ctrlr = ctrlr;
qpair->trtype = ctrlr->trid.trtype;
qpair->async = async;
STAILQ_INIT(&qpair->free_req);
for {
STAILQ_INSERT_HEAD(&qpair->free_req, req, stailq);
}
TAILQ_INSERT_TAIL(&ctrlr->active_io_qpairs, qpair, tailq);
nvme_ctrlr_proc_add_io_qpair(qpair):
TAILQ_INSERT_TAIL(&active_proc->allocated_io_qpairs, qpair, per_process_tailq);
qpair->active_proc = active_proc;
spdk_nvme_poll_group_add(nvme_poll_group, qpair):
while (transport) {
tgroup = nvme_transport_poll_group_create(transport):
nvme_rdma_poll_group_create():
STAILQ_INIT(&rdma_poll_group->pollers);
TAILQ_INIT(&rdma_poll_group->connecting_qpairs);
TAILQ_INIT(&rdma_poll_group->active_qpairs);
return rdma_poll_group->transport_poll_group;
STAILQ_INIT(&group->connected_qpairs);
STAILQ_INIT(&group->disconnected_qpairs);
tgroup->group = nvme_poll_group;
STAILQ_INSERT_TAIL(&nvme_poll_group->tgroups, tgroup, link);
}
nvme_transport_poll_group_add(tgroup, qpair):
qpair->poll_group = tgroup;
nvme_rdma_poll_group_add(tgroup, qpair):
spdk_nvme_ctrlr_connect_io_qpair(entry->u.nvme.ctrlr, qpair):
nvme_transport_ctrlr_connect_qpair(ctrlr, qpair):
nvme_qpair_set_state(qpair, NVME_QPAIR_CONNECTING);
nvme_rdma_ctrlr_connect_qpair(ctrlr, qpair):
rqpair = nvme_rdma_qpair(qpair):
SPDK_CONTAINEROF(qpair, struct nvme_rdma_qpair, qpair):
#define SPDK_CONTAINEROF(ptr, type, member) ((type *)((uintptr_t)ptr - offsetof(type, member)));
rctrlr = nvme_rdma_ctrlr(ctrlr);
nvme_parse_addr(&dst_addr, ctrlr->trid.traddr, &port, ...);
nvme_parse_addr(&src_addr, ctrlr->opts.src_addr, &src_port, ...);
rdma_create_id(rctrlr->cm_channel, &rqpair->cm_id, rqpair, RDMA_PS_TCP);
nvme_rdma_resolve_addr(rqpair, &src_addr, &dst_addr):
rdma_set_option(rqpair->cm_id, ...);
rdma_resolve_addr(rqpair->cm_id, src_addr, dst_addr, ...);
nvme_rdma_process_event_start(rqpair, RDMA_CM_EVENT_ADDR_RESOLVED = 0, nvme_rdma_addr_resolved):
rqpair->evt_cb = evt_cb;
...
rqpair->state = NVME_RDMA_QPAIR_STATE_INITIALIZING;
rgroup = nvme_rdma_poll_group(qpair->poll_group);
TAILQ_INSERT_TAIL(&rgroup->connecting_qpairs, rqpair, link_connecting);
nvme_poll_group_connect_qpair(qpair):
nvme_transport_poll_group_connect_qpair(qpair):
nvme_rdma_poll_group_connect_qpair(qpair):
STAILQ_INSERT_TAIL(&tgroup->connected_qpairs, qpair, poll_group_stailq);
while {
spdk_nvme_poll_group_process_completions(group, 0, perf_disconnect_cb):
STAILQ_FOREACH(tgroup, &group->tgroups, link) {
nvme_transport_poll_group_process_completions(tgroup, ..., disconnected_qpair_cb):
nvme_rdma_poll_group_process_completions(tgroup, ..., disconnected_qpair_cb):
TAILQ_FOREACH_SAFE(rqpair, &rgroup->connecting_qpairs, ...) {
nvme_rdma_ctrlr_connect_qpair_poll(rqpair->qpair->ctrlr, rqpair->qpair):
...
TAILQ_REMOVE(&rgroup->connecting_qpairs, rqpair, ...);
nvme_qpair_resubmit_requests(rqpair->qpair, rqpair->num_entries):
...
}
STAILQ_FOREACH_SAFE(qpair, &tgroup->connected_qpairs, ...) {
nvme_rdma_qpair_process_cm_event(rqpair);
...
}
STAILQ_FOREACH(poller, &rgroup->pollers, ...) {
nvme_rdma_cq_process_completions(poller->cq, batch_size, poller, NULL, &rdma_completions);
...
}
}
spdk_nvme_poll_group_all_connected(group):
...
}
}
}
pthread_barrier_wait(&g_worker_sync_barrier);
TAILQ_FOREACH(ns_ctx, &worker->ns_ctx, link) {
submit_io(ns_ctx, g_queue_depth);
}
while (!g_exit) {
TAILQ_FOREACH(ns_ctx, &worker->ns_ctx, link) {
ns_ctx->entry->fn_table->check_io(ns_ctx);
...
}
...
}
...
spdk_env_thread_wait_all();
print_stats();
pthread_barrier_destroy(&g_worker_sync_barrier);
...
unregister_trids();
unregister_namespaces();
unregister_controllers();
unregister_workers();
spdk_env_fini();
|